In the previous article we discussed Monte Carlo methods and their implementation in CUDA, focusing on option pricing.
Today, we take a step back from finance to introduce a couple of essential topics, which will help us to write more advanced (and efficient!) programs in the future.
In subsequent articles I will introduce multi-dimensional thread blocks and shared memory, which will be extremely helpful for several aspects of computational finance, e.g. option pricing under a binomial model and using finite difference methods (FDM) for solving PDEs.
As usual, we will learn how to deal with those subjects in CUDA by coding. In this article we will use a matrix-matrix multiplication as our main guide.
So far you should have read my other articles about starting with CUDA, so I will not explain the "routine" part of the code (i.e. everything not relevant to our discussion). But don't worry, at the end of the article you can find the complete code. Also, if you have any doubt, feel free to ask me for help in the comment section.
Matrix-Matrix Multiplication
Before starting, it is helpful to briefly recap how a matrix-matrix multiplication is computed. Let's say we have two matrices, $A$ and $B$. Assume that $A$ is a $n \times m$ matrix, which means that it has $n$ rows and $m$ columns. Also assume that $B$ is a $m \times w$ matrix. The result of the multiplication $A*B$ (which is different from $B*A$!) is a $n \times w$ matrix, which we call $M$. That is, the number of rows in the resulting matrix equals the number of rows of the first matrix $A$ and the number of columns of the second matrix $B$.
Why does this happen and how does it work? The answer is the same for both questions here. Let's take the cell $1$,$1$ (first row, first column) of $M$. The number inside it after the operation $M=A*B$ is the sum of all the element-wise multiplications of the numbers in $A$, row 1, with the numbers in $B$, column 1. That is, in the cell $i$,$j$ of $M$ we have the sum of the element-wise multiplication of all the numbers in the $i$-th row in $A$ and the $j$-th column in $B$.
The following figure intuitively explains this idea:
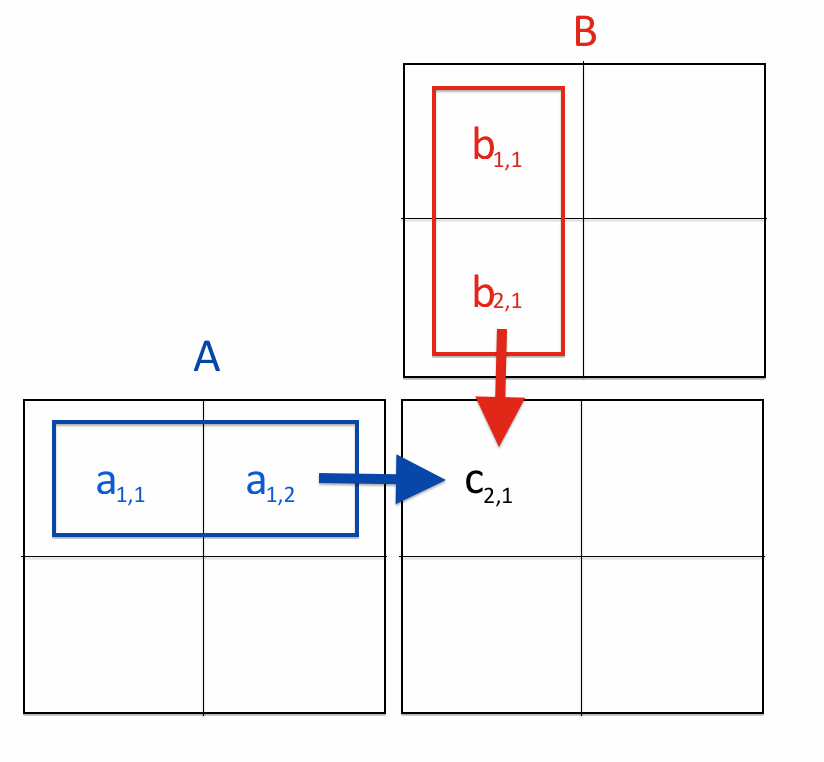
It should be pretty clear now why matrix-matrix multiplication is a good example for parallel computation. We have to compute every element in $C$, and each of them is independent from the others, so we can efficiently parallelise.
We will see different ways of achieving this. The goal is to add new concepts throughout this article, ending up with a 2D kernel, which uses shared memory to efficiently optimise operations.
Grids And Blocks
After the previous articles, we now have a basic knowledge of CUDA thread organisation, so that we can better examine the structure of grids and blocks.
When we call a kernel using the instruction <<< >>> we automatically define a dim3 type variable defining the number of blocks per grid and threads per block.
In fact, grids and blocks are 3D arrays of blocks and threads, respectively. This is evident when we define them before calling a kernel, with something like this:
dim3 blocksPerGrid(512, 1, 1)
dim3 threadsPerBlock(512, 1, 1)
kernel<<<blocksPerGrid, threadsPerBlock>>>()
In the previous articles you didn't see anything like that, as we only discussed 1D examples, in which we didn't have to specify the other dimensions. This is because, if you only give a number to the kernel call as we did, it is assumed that you created a dim3 mono-dimensional variable, implying $y=1$ and $z=1$.
As we are dealing with matrices now, we want to specify a second dimension (and, again, we can omit the third one). This is very useful, and sometimes essential, to make the threads work properly.
Indeed, in this way we can refer to both the $x$ and $y$ axis in the very same way we followed in previous examples. Let's have a look at the code:
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
As you can see, it's similar code for both of them. In CUDA, blockIdx, blockDim and threadIdx are built-in functions with members x, y and z. They are indexed as normal vectors in C++, so between 0 and the maximum number minus 1. For instance, if we have a grid dimension of blocksPerGrid = (512, 1, 1), blockIdx.x will range between 0 and 511.
As I mentioned here the total amount of threads in a single block cannot exceed 1024.
Using a multi-dimensional block means that you have to be careful about distributing this number of threads among all the dimensions. In a 1D block, you can set 1024 threads at most in the x axis, but in a 2D block, if you set 2 as the size of y, you cannot exceed 512 for the x! For example, dim3 threadsPerBlock(1024, 1, 1) is allowed, as well as dim3 threadsPerBlock(512, 2, 1), but not dim3 threadsPerBlock(256, 3, 2).
Linearise Multidimensional Arrays
In this article we will make use of 1D arrays for our matrixes. This might sound a bit confusing, but the problem is in the programming language itself. The standard upon which CUDA is developed needs to know the number of columns before compiling the program. Hence it is impossible to change it or set it in the middle of the code.
However, a little thought shows that this is not a big issue. We cannot use the comfortable notation A[i][j], but we won't struggle that much as we already know how to properly index rows and columns.
In fact, the easiest way to linearize a 2D array is to stack each row lengthways, from the first to the last. The following picture will make this concept clearer:
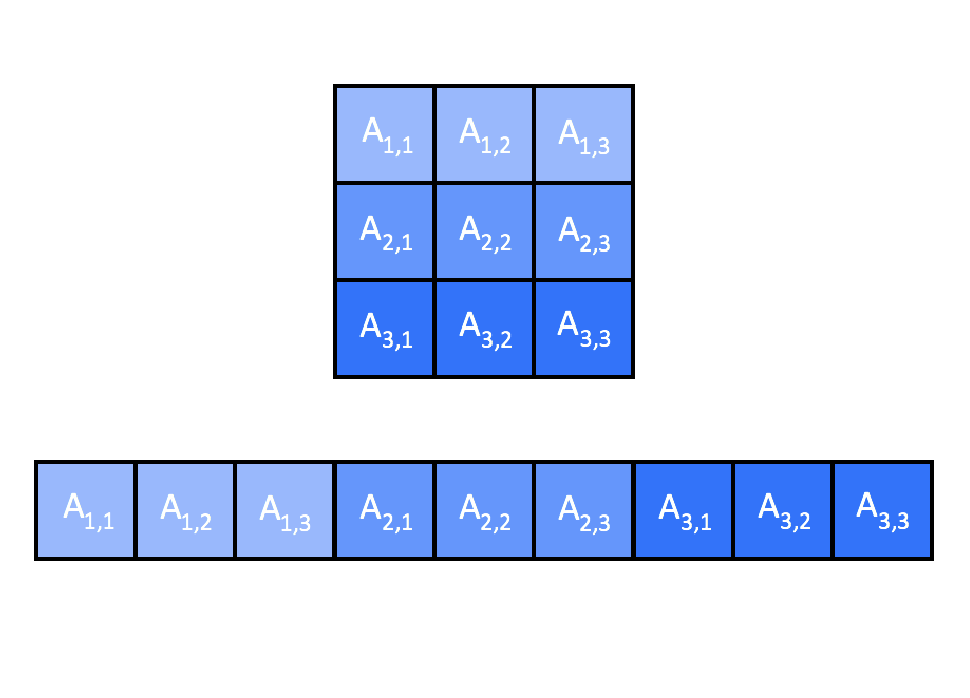
The Kernel
Now that we have all the necessary information for carrying out the task, let's have a look at the kernel code. For sake of simplicity we will use square $N \times N$ matrices in our example.
The first thing to do, as we already saw, is to determine the $x$ and $y$ axis index (i.e. row and column numbers):
__global__ void multiplication(float *A, float* B, float *C, int N){
int ROW = blockIdx.y*blockDim.y+threadIdx.y;
int COL = blockIdx.x*blockDim.x+threadIdx.x;
Then, we check that the row and column total does not exceed the number of actual rows and columns in the matrices. As the threads will access the memory in random order, we have to do this for preventing unnecessary threads from performing operations on our matrices. That is, we are making blocks and grids of a certain size, so that if we don't set our $N$ as a multiple of that size, we would have more threads than we need:
if (ROW < N && COL < N) {
We won't have any problem here as we are using square matrices, but it's always a good idea to keep this in mind. We then have to initialise the temporary variable tmp_sum for summing all the cells in the selected row and column. It is always a good procedure to specify the decimal points and the f even if they are zeroes. So let's write:
float tmp_sum = 0.0f;
Now the straightforward part: as for the CPU code, we can use a for loop for computing the sum and then store it in the corresponding C cell.
for (int i = 0; i < N; i++) {
tmpSum += A[ROW * N + i] * B[i * N + COL];
}
C[ROW * N + COL] = tmpSum;
The host (CPU) code starts by declaring variables in this way:
int main() {
// declare arrays and variables
int N = 16;
int SIZE = N*N;
vector<float> h_A(SIZE);
vector<float> h_B(SIZE);
vector<float> h_C(SIZE);
Note that, given the if condition in the kernel, we could set $N$ values that are not necessarily a multiple of the block size. Also, I will make use of the library dev_array, which I discussed in this article.
Now let's fill the matrices. There are several ways to do this, such as making functions for manual input or using random numbers. In this case, we simply use a for loop to fill the cells with trigonometric values of the indices:
for (int i=0; i<N; i++){
for (int j=0; j<N; j++){
h_A[i*N+j] = sin(i);
h_B[i*N+j] = cos(j);
}
}
Recalling the "Grids and Blocks" paragraph, we now have to set the dim3 variables for both blocks and grids dimensions. The grid is just a BLOCK_SIZE $\times$ BLOCK_SIZE grid, so we can write:
dim3 threadsPerBlock (BLOCK_SIZE, BLOCK_SIZE)
As we are not working only with matrices with a size multiple of BLOCK_SIZE, we have to use the ceil instruction, to get the next integer number as our size, as you can see:
int n_blocks = ceil(N/BLOCK_SIZE);
dim3 blocksPerGrid (n_blocks, n_blocks)
Note that in this way we will use more threads than necessary, but we can prevent them working on our matrices with the if condition we wrote in the kernel.
This is the general solution showing the reasoning behind it all, but in the complete code you will find a more efficient version of it in kernel.cu.
Now we only have to create the device arrays, allocate memory on the device and call our kernel and, a as result, we will have a parallel matrix multiplication program. Using dev_array, we simply write:
dev_array<float> d_A(SIZE);
dev_array<float> d_B(SIZE);
dev_array<float> d_C(SIZE);
for declaring arrays and:
d_A.set(&h_A[0], SIZE);
d_B.set(&h_B[0], SIZE);
for allocating memory. For getting the device results and copying it on the host, we use the get method instead. Once again, this is simply:
d_C.get(&h_C[0], SIZE);
At the bottom of this page you can find the complete code, including performance comparison and error computation between the parallel and the serial code.
In the next article I will discuss the different types of memory and, in particular, I will use the shared memory for speeding-up the matrix multiplication. But don't worry, just after this we will come back to an actual finance application by applying what we learned so far to financial problems.
Full Code
dev_array.h
#ifndef _DEV_ARRAY_H_
#define _DEV_ARRAY_H_
#include <stdexcept>
#include <algorithm>
#include <cuda_runtime.h>
template <class T>
class dev_array
{
// public functions
public:
explicit dev_array()
: start_(0),
end_(0)
{}
// constructor
explicit dev_array(size_t size)
{
allocate(size);
}
// destructor
~dev_array()
{
free();
}
// resize the vector
void resize(size_t size)
{
free();
allocate(size);
}
// get the size of the array
size_t getSize() const
{
return end_ - start_;
}
// get data
const T* getData() const
{
return start_;
}
T* getData()
{
return start_;
}
// set
void set(const T* src, size_t size)
{
size_t min = std::min(size, getSize());
cudaError_t result = cudaMemcpy(start_, src, min * sizeof(T), cudaMemcpyHostToDevice);
if (result != cudaSuccess)
{
throw std::runtime_error("failed to copy to device memory");
}
}
// get
void get(T* dest, size_t size)
{
size_t min = std::min(size, getSize());
cudaError_t result = cudaMemcpy(dest, start_, min * sizeof(T), cudaMemcpyDeviceToHost);
if (result != cudaSuccess)
{
throw std::runtime_error("failed to copy to host memory");
}
}
// private functions
private:
// allocate memory on the device
void allocate(size_t size)
{
cudaError_t result = cudaMalloc((void**)&start_, size * sizeof(T));
if (result != cudaSuccess)
{
start_ = end_ = 0;
throw std::runtime_error("failed to allocate device memory");
}
end_ = start_ + size;
}
// free memory on the device
void free()
{
if (start_ != 0)
{
cudaFree(start_);
start_ = end_ = 0;
}
}
T* start_;
T* end_;
};
#endif
matrixmul.cu
#include <iostream>
#include <vector>
#include <stdlib.h>
#include <time.h>
#include <cuda_runtime.h>
#include "kernel.h"
#include "kernel.cu"
#include "dev_array.h"
#include <math.h>
using namespace std;
int main()
{
// Perform matrix multiplication C = A*B
// where A, B and C are NxN matrices
int N = 16;
int SIZE = N*N;
// Allocate memory on the host
vector<float> h_A(SIZE);
vector<float> h_B(SIZE);
vector<float> h_C(SIZE);
// Initialize matrices on the host
for (int i=0; i<N; i++){
for (int j=0; j<N; j++){
h_A[i*N+j] = sin(i);
h_B[i*N+j] = cos(j);
}
}
// Allocate memory on the device
dev_array<float> d_A(SIZE);
dev_array<float> d_B(SIZE);
dev_array<float> d_C(SIZE);
d_A.set(&h_A[0], SIZE);
d_B.set(&h_B[0], SIZE);
matrixMultiplication(d_A.getData(), d_B.getData(), d_C.getData(), N);
cudaDeviceSynchronize();
d_C.get(&h_C[0], SIZE);
cudaDeviceSynchronize();
float *cpu_C;
cpu_C=new float[SIZE];
// Now do the matrix multiplication on the CPU
float sum;
for (int row=0; row<N; row++){
for (int col=0; col<N; col++){
sum = 0.f;
for (int n=0; n<N; n++){
sum += h_A[row*N+n]*h_B[n*N+col];
}
cpu_C[row*N+col] = sum;
}
}
double err = 0;
// Check the result and make sure it is correct
for (int ROW=0; ROW < N; ROW++){
for (int COL=0; COL < N; COL++){
err += cpu_C[ROW * N + COL] - h_C[ROW * N + COL];
}
}
cout << "Error: " << err << endl;
return 0;
}
kernel.h
#ifndef KERNEL_CUH_
#define KERNEL_CUH_
void matrixMultiplication(float *A, float *B, float *C, int N);
#endif
kernel.cu
#include <math.h>
#include <iostream>
#include "cuda_runtime.h"
#include "kernel.h"
#include <stdlib.h>
using namespace std;
__global__ void matrixMultiplicationKernel(float* A, float* B, float* C, int N) {
int ROW = blockIdx.y*blockDim.y+threadIdx.y;
int COL = blockIdx.x*blockDim.x+threadIdx.x;
float tmpSum = 0;
if (ROW < N && COL < N) {
// each thread computes one element of the block sub-matrix
for (int i = 0; i < N; i++) {
tmpSum += A[ROW * N + i] * B[i * N + COL];
}
}
C[ROW * N + COL] = tmpSum;
}
void matrixMultiplication(float *A, float *B, float *C, int N){
// declare the number of blocks per grid and the number of threads per block
// use 1 to 512 threads per block
dim3 threadsPerBlock(N, N);
dim3 blocksPerGrid(1, 1);
if (N*N > 512){
threadsPerBlock.x = 512;
threadsPerBlock.y = 512;
blocksPerGrid.x = ceil(double(N)/double(threadsPerBlock.x));
blocksPerGrid.y = ceil(double(N)/double(threadsPerBlock.y));
}
matrixMultiplicationKernel<<<blocksPerGrid,threadsPerBlock>>>(A, B, C, N);
}


