Almost a year ago QuantStart discussed deep learning and introduced the Theano library via a logistic regression example. Given the recent results of the QuantStart 2017 Content Survey it was decided that an up to date beginner-friendly article was needed to introduce deep learning from first principles.
These days it is almost impossible to work in any technology-heavy field without hearing about the latest advances in the field of deep learning. Quantitative finance is no different. Many of the recent discussions in the latest quant finance conferences such as Quantopian's QuantCon and Newsweek's AI & Data Science - Capital Markets are largely focusing around the promise of deep learning as the next frontier in quantitative trading.
Unfortunately the field of deep learning has a reputation for being difficult, rapidly-changing and inpenetrable without a PhD in computational neuroscience. This indeed may have been the case five years ago but recent advances in open source libraries and availability of massively-parallel hardware have opened up the field to those armed only with a basic knowledge of programming.
This long-term series of articles on deep learning will provide guidance to those quants who are completely new to the field. They will attempt to take a complete deep learning novice to an individual who can usefully contribute to the community and carry out their own deep learning research for quantitative trading purposes.
In this particular article an introduction to deep learning will be provided. The concepts of representations and hierarchical feature learning will be outlined. Subsequently its application to quantitative trading will be considered and whether it holds any promise in this area.
Deep Learning: An Introduction
Deep learning is a subset of the broader field of machine learning (Murphy, 2012), which itself is an interdisciplinary research area across mathematics, statistics, computer science and neuroscience. Within the last five years deep learning has broken out of the academic domain to become the dominant machine learning technique in use within many high-technology industries.
Demonstrating BB8, Nvidia's Self-Driving Car
Deep learning has found applications across the Artificial Intelligence (AI) spectrum including self-driving cars (Nvidia, 2017), robotics (Levine et al, 2016), text-to-speech (van den Oord et al, 2016), speech recognition (Yu and Deng, 2014), language translation (Cho et al, 2014), image style transfer (Gatys et al, 2016), automatic content generation (Goodfellow et al, 2014) as well as world-class, human-beating performance at board- and video-games from the Atari 2600 (Mnih et al, 2015) to the ancient game of Go (Silver et al, 2016).
![]()
Examples of Image Style Transfer from (Gatys et al, 2015)
While the above applications have generated wide coverage in the popular press many of the techniques have found uses in more traditional industrial settings. This includes anomaly detection (Zhai, 2016) and control systems optimisation (Gao, 2014).
The rate of progress in deep learning has been explosive. The extremely open community blends academia, industry and finance, providing extensive real-world datasets on which to train the ever-growing set of models.

DeepMind Deep Q-Network playing Atari 2600 "Breakout" from kuz
An open publishing format predominantly using the arXiv pre-print server enables rapid dissemination of results. Open source libraries such as Caffe, Torch, Theano, Tensorflow and Keras have all but mitigated the complexities of implementing new architectures. Reproducibility is extensive via implementations of models on open source version control repositories such as Github.

Nvidia Geforce GTX 1080 Ti GPU
Recent advances in parallel computing architectures have enabled academic labs and individuals to carry out research on commodity hardware such as consumer-grade Graphics Processing Units (GPU)–either on cheap local workstations or via on-demand cloud-based parallel compute nodes.
The confluence of these trends has lead to incredibly impressive results, along with a huge degree of popular hype, surrounding deep learning.
What is Deep Learning?
Representations
The motivation for deep learning techniques begins with a discussion on the broader field of machine learning. Machine learning can be considered as a mechanism for mapping representations of data to outcomes (Goodfellow et al, 2016).
In quantitative trading this often manifests itself as handcrafting "indicators" on financial pricing data in order to predict the following day's asset price.
The performance of these trading models is highly dependent upon the quality of these indicators or features–that is, the representations of the underlying prices.
This can be seen by simply using the raw lagged pricing information itself as features. For certain well-traded assets the underlying prices do not correlate well with predictive outcomes. This is due to the low signal-to-noise ratio in most asset class price histories. It means careful handcrafting of features is needed in order to extract useful predictive signals. In essence, it is the choice of feature representation that is important.
Thus the fundamental task of the quant trading researcher is to figure out which features provide useful predictive signal. Not only is this task extremely time-consuming but it also requires constant diligence due to the presence of "alpha decay", wherein predictive signals are eventually arbitraged away.
One potential solution to this issue is to use machine learning techniques to not only learn the mappings from the predictors to the responses–once the predictors have been handcrafted–but also to actually learn the predictors themselves. That is, for the machine learning models to use the data to learn the best representation that produces predictive signal.
In certain fields this can produce performance far in excess of human crafted features. In addition it frees up a substantial portion of research time, since these handcrafted features do not need to be found in a manual fashion.
Hierarchical Features
This is where deep learning comes in. It "solves" the problem of feature crafting by introducing a hierarchy into the feature representations. By learning simple concepts and then building on these concepts to form more complex examples it is possible to produce highly predictive sets of feature representations that vastly exceed those developed by humans.
As an example from the field of computer vision a convolutional neural network will use many hidden layers to take image input pixels, form edges from these pixels, form corners/contours from these edges and thus recognise objects from patterns of corners and edges.

Example filters in the "AlexNet" Convolutional Neural Network (Krizhevsky et al, 2012). Note the various "edge detection" filters.
The key insight is that the pixel information in its raw representation is not well correlated with objects in the image. It is only by using a hierachical set of non-linear feature transformations in a "deep" network that the predictive signal becomes extremely strong.
This approach is motivated by how the human brain is thought to work. Over the course of a human lifetime simple ideas are learned, which are used to form hierarchies of more complex ideas. Deep learning is about applying this approach to machine learning tasks.
However, deep learning is not a new idea. It is effectively a "rebranding" of the well-known field of Artificial Neural Networks. Advances in computing power, software engineering and available datasets have meant that older "shallow" neural networks have given way to "deep" neural networks with various architectures often with many "hidden layers".
Why Now?
The algorithms underlying deep neural networks–including backpropagation and stochastic gradient descent–have been around for a long time. So why is it that deep learning has only begun to show significant promise?
Primarily it is because only now is it possible to provide these algorithms with the resources they need to produce such impressive results.
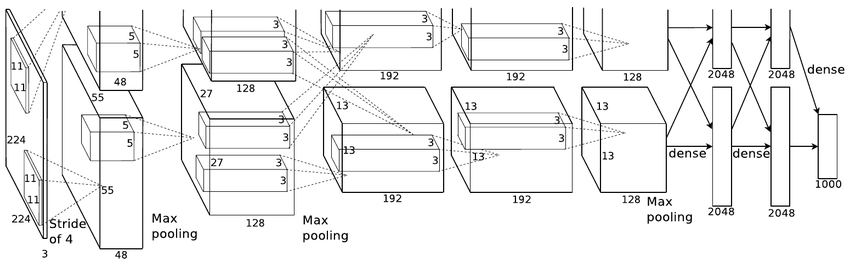
"AlexNet" Convolutional Neural Network architecture (Krizhevsky et al, 2012)
Such resources include an abundance of extremely well-labelled training data and the availability of cheap parallelisable hardware, which is straightforward to write software for.
The incredible growth of the internet has, as a by-product, produced vast swathes of recorded time series, text, images, audio and video–much of which is labelled. The advent of the Graphics Processing Unit (GPU) means that such datasets can be processed in a reasonable amount of time.

Nvidia Tesla P100 GPU
Combining these extensive datasets with highly-parallelisable hardware has allowed modern deep learning models to vastly exceed human performance at many classification tasks, often with minimal human intervention.
Deep Learning for Quant Trading
While deep learning is a relatively new field of research it is already showing significant promise in the field of finance. Some interesting research has been published in the last couple of years:
- Commodity and forex futures directions have been predicted by deep neural networks (Dixon et al, 2016)
- The momentum effect in equities has been analysed to predict both higher and lower monthly/daily returns than the median in (Takeuchi and Lee, 2013) and (Batres-Estrada, 2015).
- Deep learning based natural language processing techniques have been applied to predict distress in financial firms (Rönnqvist and Sarlin, 2016) as well as predicting German equity returns based on news headlines (Fehrer and Feuerriegel, 2015).
It was also mentioned in a previous article how deep neural networks for image recognition were being used to detect static oil storage tanks with floating lids, as a means of estimating world crude oil supplies.
Ultimately much of the success of supervised deep learning comes in automatic feature extraction. However it does require a significant amount of training data, with reasonable signal-to-noise ratios in order to be effective.
Hence the challenge in quant finance is to try and obtain vast quantities of financial training data that contains useful signal. In subsequent articles these points will be adressed at length.
What's Next?
In subsequent articles the common deep learning architectures will be outlined, including the multilayer perceptron (MLP), the convolutional neural network (CNN) and the recurrent neural network (RNN).
Two Python-based deep learning libraries will be introduced and installed, namely Tensorflow and Keras. The above architectures will be implemented in Keras to demonstrate its ease of use. In addition the basic mathematical prerequisites for deep learning research will be outlined.
A "deep learning PC" build-guide will also be presented, providing detailed instructions on how to construct a cheap deep learning PC from scratch for your algorithmic trading.
Finally, subsequent articles will dedicate significant time to applying deep learning models to quantitative finance problems.
Bibliographic Note
An extremely detailed reference text on the field of machine learning at the late undergraduate/early graduate level is (Murphy, 2012).
A recent comprehensive text on deep learning that assumes an undergraduate computer science, mathematics or physics background is (Goodfellow, 2016). It covers both the well-known architectures such as the multilayer perceptron, convolutional neural network and recurrent neural networks, as well as providing chapters on the latest avenues of research.
A recent Nature survey paper by the "three giants" of deep learning (LeCun et al, 2015) provides a high-level overview of the state-of-the-art. It is a worthwhile place to begin a literature survey for those interested in deep learning research.
A more gentle introduction into deep learning is given in the slide presentation of (Beam, 2017).
References
- [1] Murphy, K.P. (2012) Machine Learning - A Probabilistic Perspective, MIT Press
- [2] Nvidia Corp. (2017) Introducing the New Nvidia Drive PX 2, http://www.nvidia.com/object/drive-px.html
- [3] Levine, S., Pastor, P., Krizhevsky, A., Quillen, D. (2016) "Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection", 1603.02199
- [4] van den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A.W., Kavukcuoglu, K. (2016) "WaveNet: A Generative Model for Raw Audio, 1609.03499"
- [5] Yu, D., Deng, L. (2014) Automatic Speech Recognition: A Deep Learning Approach, Springer
- [6] Cho, K., van Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y. (2014) "Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation, 1406.1078"
- [7] Gatys, L.A., Ecker, A.S., Bethge, M. (2016) "Image Style Transfer Using Convolutional Neural Networks", Computer Vision and Pattern Recognition
- [8] Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y. (2014) "Generative Adversarial Networks, 1406.2661"
- [9] Mnih, V. et al (2015) "Human-level control through deep reinforcement learning", Nature 518: 529–533
- [10] Silver, D. et al (2016) "Mastering the game of Go with deep neural networks and tree search", Nature 529: 484-489
- [11] Goodfellow, I.J., Bengio, Y., Courville, A. (2016) Deep Learning, MIT Press
- [12] LeCun, Y., Bengio, Y., Hinton, G. (2015) "Deep learning", Nature 521 436-444
- [13] Beam, A. (2017) Deep Learning 101, http://slides.com/beamandrew/deep-learning-101#/
- [14] Dixon, M.F., Klabjan, D., Bang, J.H. (2016) "Classification-Based Financial Markets Prediction Using Deep Neural Networks", Algorithmic Finance
- [15] Takeuchi, L., Lee, Y. (2013) "Applying Deep Learning to Enhance Momentum Trading Strategies in Stocks"
- [16] Batres-Estrada, B. (2015) "Deep learning for multivariate financial time series", Masters Thesis
- [17] Rönnqvist, S., Sarlin, P. (2016) "Bank distress in the news: Describing events through deep learning, 1603.05670"
- [18] Zhai, S., Cheng, Y., Lu, W., Zhang, Z. (2016) "Deep Structured Energy Based Models for Anomaly Detection, 1605.07717"
- [19] Gao, J. (2014) "Machine Learning Applications for Data Center Optimization", Google
- [20] Gatys, L.A., Ecker, A.S., Bethge, M. (2015) "A Neural Algorithm of Artistic Style, 1508.06576"
- [21] Krizhevsky, A., Sutskever, I., Hinton, G. (2012) "ImageNet Classification with Deep Convolutional Neural Networks", Advances in Neural Information Processing Systems 25 (NIPS 2012)
- [22] Fehrer, R., Feuerriegel, S. (2015) "Improving Decision Analytics with Deep Learning: The Case of Financial Disclosures, 1508.01993"


