A consistent challenge for quantitative traders is the frequent behaviour modification of financial markets, often abruptly, due to changing periods of government policy, regulatory environment and other macroeconomic effects. Such periods are known colloquially as "market regimes" and detecting such changes is a common, albeit difficult process undertaken by quantitative market participants.
These various regimes lead to adjustments of asset returns via shifts in their means, variances/volatilities, serial correlation and covariances, which impact the effectiveness of time series methods that rely on stationarity. In particular it can lead to dynamically-varying correlation, excess kurtosis ("fat tails"), heteroskedasticity (clustering of serial correlation) as well as skewed returns.
This motivates a need to effectively detect and categorise these regimes in order to optimally select deployments of quantitative trading strategies and optimise the parameters within them. The modeling task then becomes an attempt to identify when a new regime has occurred and adjust strategy deployment, risk management and position sizing criteria accordingly.
A principal method for carrying out regime detection is to use a statistical time series technique known as a Hidden Markov Model[2]. These models are well suited to the task as they involve inference on "hidden" generative processes via "noisy" indirect observations correlated to these processes. In this instance the hidden, or latent process is the underlying regime state, while the asset returns are the indirect noisy observations that are influenced by these states.
This article series will discuss the mathematical theory behind Hidden Markov Models (HMM) and how they can be applied to the problem of regime detection for quantitative trading purposes.
The discussion will begin by introducing the concept of a Markov Model[1] and their associated categorisation, which depends upon the level of autonomy in the system as well as how much information about the system is observed. The discussion will then focus specifically on the architecture of HMM as an autonomous process, with partially observable information.
As with previous discussions on other state space models and the Kalman Filter, the inferential concepts of filtering, smoothing and prediction will be outlined. Specific algorithms such as the Forward Algorithm[6] and Viterbi Algorithm[7] that carry out these tasks will not be presented as the focus of the discussion rests firmly in applications of HMM to quant finance, rather than algorithm derivation.
In subsequent articles the HMM will be applied to various assets to detect regimes. These detection overlays will then be added to a set of quantitative trading strategies via a "risk manager". This will be used to assess how algorithmic trading performance varies with and without regime detection.
Markov Models
Prior to the discussion on Hidden Markov Models it is necessary to consider the broader concept of a Markov Model. A Markov Model is a stochastic state space model involving random transitions between states where the probability of the jump is only dependent upon the current state, rather than any of the previous states. The model is said to possess the Markov Property and is "memoryless". Random Walk models are another familiar example of a Markov Model.
Markov Models can be categorised into four broad classes of models depending upon the autonomy of the system and whether all or part of the information about the system can be observed at each state. The Markov Model page at Wikipedia[1] provides a useful matrix that outlines these differences, which will be repeated here:
| Fully Observable | Partially Observable | |
|---|---|---|
| Autonomous | Markov Chain[5] | Hidden Markov Model[2] |
| Controlled | Markov Decision Process[3] | Partially Observable Markov Decision Process[4] |
The simplest model, the Markov Chain, is both autonomous and fully observable. It cannot be modified by actions of an "agent" as in the controlled processes and all information is available from the model at any state. A good example of a Markov Chain is the Markov Chain Monte Carlo (MCMC) algorithm used heavily in computational Bayesian inference.
If the model is still fully autonomous but only partially observable then it is known as a Hidden Markov Model. In such a model there are underlying latent states (and probability transitions between them) but they are not directly observable and instead influence the "observations". An important point is that while the latent states do possess the Markov Property there is no need for the observation states to do so. The most common use of HMM outside of quantitative finance is in the field of speech recognition.
Once the system is allowed to be "controlled" by an agent(s) then such processes come under the heading of Reinforcement Learning (RL), often considered to be the third "pillar" of machine learning along with Supervised Learning and Unsupervised Learning. If the system is fully observable, but controlled, then the model is called a Markov Decision Process (MDP). A related technique is known as Q-Learning[11], which is used to optimise the action-selection policy for an agent under a Markov Decision Process model. In 2015 Google DeepMind pioneered the use of Deep Reinforcement Networks, or Deep Q Networks, to create an optimal agent for playing Atari 2600 video games solely from the screen buffer[12].
If the system is both controlled and only partially observable then such Reinforcement Learning models are termed Partially Observable Markov Decision Processes (POMDP). Techniques to solve high-dimensional POMDP are the subject of much current academic research. The non-profit team at OpenAI spend significant time looking at such problems and have released an open-source toolkit, or "gym", to allow straightforward testing of new RL agents known as the OpenAI Gym[13].
Unfortunately Reinforcement Learning, along with MDP and POMDP, are not within the scope of this article. However they will be the subject of later articles, particularly as the article series on Deep Learning is further developed.
Note that in this article continuous-time Markov processes are not considered. In quantitative trading the time unit is often given via ticks or bars of historical asset data. However, if the objective is to price derivatives contracts then the continuous-time machinery of stochastic calculus would be utilised.
Markov Model Mathematical Specification
This section as well as that on the Hidden Markov Model Mathematical Specification will closely follow the notation and model specification of Murphy (2012)[8].
In quantitative finance the analysis of a time series is often of primary interest. Such a time series generally consists of a sequence of $T$ discrete observations $X_1, \ldots, X_T$. An important assumption about Markov Chain models is that at any time $t$, the observation $X_t$ captures all of the necessary information required to make predictions about future states. This assumption will be utilised in the following specification.
Formulating the Markov Chain into a probabilistic framework allows the joint density function for the probability of seeing the observations to be written as:
\begin{eqnarray} p(X_{1:T}) &=& p(X_1)p(X_2 \mid X_1)p(X_3 \mid X_2)\ldots \\ &=& p(X_1) \prod^{T}_{t=2} p(X_t \mid X_{t-1}) \end{eqnarray}
This states that the probability of seeing sequences of observations is given by the probability of the initial observation multiplied $T-1$ times by the conditional probability of seeing the subsequent observation, given the previous observation has occurred. It will be assumed in this article that the latter term, known as the transition function, $p(X_t \mid X_{t-1})$ will itself be time-independent.
In addition, since the market regime models considered in this article series will consist of a small, discrete number of regimes (or "states"), say $K$, the type of model under consideration is known as a Discrete-State Markov Chain (DSMC).
Thus if there are $K$ separate possible states, or regimes, for the model to be in at any time $t$ then the transition function can be written as a transition matrix that describes the probability of transitioning from state $j$ to state $i$ at any time-step $t$. Mathematically, the elements of the transition matrix $A$ are given by:
\begin{eqnarray} A_{ij} = p(X_t = j \mid X_{t-1} = i) \end{eqnarray}
As an example it is possible to consider a simple two-state Markov Chain Model. The following diagram represents the numbered states as circles while the arcs represent the probability of jumping from state to state:
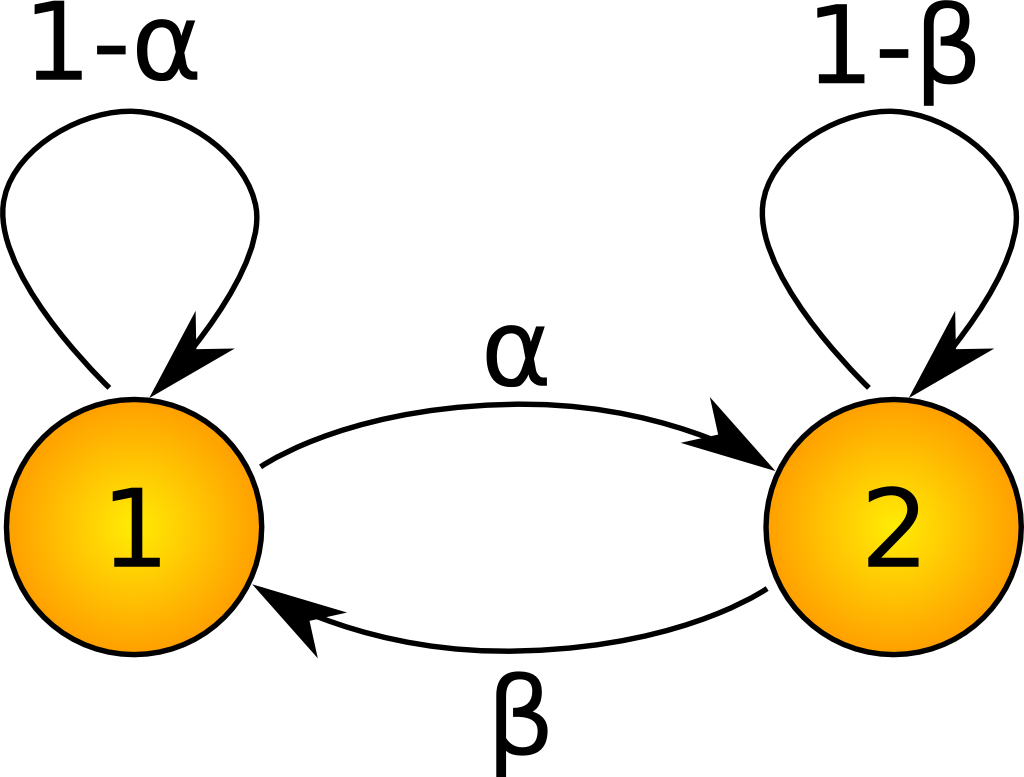
Two-state Markov Chain Model
Notice that the probabilities sum to unity for each state, i.e. $\alpha + (1 - \alpha) = 1$. The transition matrix $A$ for this system is a $2 \times 2$ matrix given by:
\begin{eqnarray} A = \left( \begin{array}{cc} 1-\alpha & \alpha \\ \beta & 1-\beta \end{array} \right) \end{eqnarray}
In order to simulate $n$ steps of a general DSMC model it is possible to define the $n$-step transition matrix $A(n)$ as:
\begin{eqnarray} A_{ij}(n) := p(X_{t+n} = j \mid X_t = i) \end{eqnarray}
It can be easily shown that $A(m+n)=A(m)A(n)$ and thus that $A(n)=A(1)^n$. This means that $n$ steps of a DSMC model can be simulated simply by repeated multiplication of the transition matrix with itself.
Hidden Markov Models
Hidden Markov Models are Markov Models where the states are now "hidden" from view, rather than being directly observable. Instead there are a set of output observations, related to the states, which are directly visible. To make this concrete for a quantitative finance example it is possible to think of the states as hidden "regimes" under which a market might be acting while the observations are the asset returns that are directly visible.
In a Markov Model it is only necessary to create a joint density function for the observations. A time-invariant transition matrix was specified allowing full simulation of the model. For Hidden Markov Models it is necessary to create a set of discrete states $z_t \in \{1,\ldots, K \}$ (although for purposes of regime detection it is often only necessary to have $K \leq 3$) and to model the observations with an additional probability model, $p({\bf x}_t \mid z_t)$. That is, the conditional probability of seeing a particular observation (asset return) given that the state (market regime) is currently equal to $z_t$.
Depending upon the specified state and observation transition probabilities a Hidden Markov Model will tend to stay in a particular state and then suddenly jump to a new state and remain in that state for some time. This is precisely the behaviour that is desired from such a model when trying to apply it to market regimes. The regimes themselves are not expected to change too quickly (consider regulatory changes and other slow-moving macroeconomic effects). However, when they do change they are expected to persist for some time.
Hidden Markov Model Mathematical Specification
The corresponding joint density function for the HMM is given by (again using notation from Murphy (2012)[8]):
\begin{eqnarray} p({\bf z}_{1:T} \mid {\bf x}_{1:T}) &=& p({\bf z}_{1:T}) p ({\bf x}_{1:T} \mid {\bf z}_{1:T}) \\ &=& \left[ p(z_1) \prod_{t=2}^{T} p(z_t \mid z_{t-1}) \right] \left[ \prod_{t=1}^T p({\bf x}_t \mid z_t) \right] \end{eqnarray}
In the first line this states that the joint probability of seeing the full set of hidden states and observations is equal to the probability of simply seeing the hidden states multiplied by the probability of seeing the observations, conditional on the states. This makes sense as the observations cannot affect the states, but the hidden states do indirectly affect the observations.
The second line splits these two distributions into transition functions. The transition function for the states is given by $p(z_t \mid z_{t-1})$ while that for the observations (which depend upon the states) is given by $p({\bf x}_t \mid z_t)$.
As with the Markov Model description above it will be assumed for the purposes of this article that both the state and observation transition functions are time-invariant. This means that it is possible to utilise the $K \times K$ state transition matrix $A$ as before with the Markov Model for that component of the model.
However, for the application considered here, namely observations of asset returns, the values are in fact continuous. This means the model choice for the observation transition function is more complex. The common choice is to make use of a conditional multivariate Gaussian distribution with mean ${\bf \mu}_k$ and covariance ${\bf \sigma}_k$. This is formalised below:
\begin{eqnarray} p({\bf x}_t \mid z_t = k, {\bf \theta}) = \mathcal{N}({\bf x}_t \mid {\bf \mu}_k, {\bf \sigma}_k) \end{eqnarray}
That is, if the state $z_t$ is currently equal to $k$, then the probability of seeing observation ${\bf x}_t$, given the parameters of the model $\theta$, is distributed as a multivariate Guassian.
In order to make this a little clearer the following diagram shows the evolution of the states $z_t$ and how they lead indirectly to the evolution of the observations, ${\bf x}_t$:
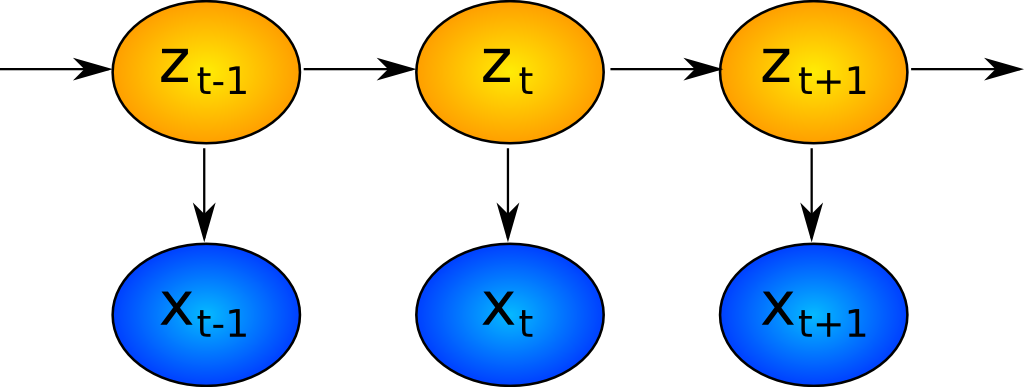
Hidden Markov Model: States and Observations
Filtering of Hidden Markov Models
With the joint density function specified it remains to consider the how the model will be utilised. In general state-space modelling there are often three main tasks of interest: Filtering, Smoothing and Prediction. The previous article on state-space models and the Kalman Filter describe these briefly. They will be repeated here for completeness:
- Prediction - Forecasting subsequent values of the state
- Filtering - Estimating the current values of the state from past and current observations
- Smoothing - Estimating the past values of the state given the observations
Filtering and smoothing are similar, but not identical. Smoothing is concerned with wanting to understand what has happened to states in the past given current knowledge, whereas filtering is concerned with what is happening with the state right now.
It is beyond the scope of this article to describe in detail the algorithms developed for filtering, smoothing and prediction. The main goal of this article series is to apply Hidden Markov Models to Regime Detection. Hence the task at hand becomes determining what the current "market regime state" the world is in utilising the asset returns available to date. Thus this is a filtering problem.
Mathematically the conditional probability of the state at time $t$ given the sequence of observations up to time $t$ is the object of interest. This involves determining $p(z_t \mid {\bf x}_{1:T})$. As with the Kalman Filter it is possible to recursively apply Bayes rule in order to achieve filtering on an HMM.
Next Steps
In the second article of the series regime detection for financial assets will be discussed in greater depth. In addition libraries from the Python language will be applied to historical asset returns in order to produce a regime detection tool that will ultimately be used as a risk management tool for quantitative trading.
Bibliographic Note
An overview of Markov Models (as well as their various categorisations), including Hidden Markov Models (and algorithms to solve them), can be found in the introductory articles on Wikipedia[1], [2], [3], [4], [5], [6], [7].
A highly detailed textbook mathematical overview of Hidden Markov Models, with applications to speech recognition problems and the Google PageRank algorithm, can be found in Murphy (2012)[8]. Bishop (2007)[8] covers similar ground to Murphy (2012), including the derivation of the Maximum Likelihood Estimate (MLE) for the HMM as well as the Forward-Backward and Viterbi Algorithms. The discussion concludes with Linear Dynamical Systems and Particle Filters.
References
- [1] (2016). Markov Model, Wikipedia
- [2] (2016). Hidden Markov Model, Wikipedia
- [3] (2016). Markov Decision Process, Wikipedia
- [4] (2016). Partially observable Markov decision process, Wikipedia
- [5] (2016). Markov Chain, Wikipedia
- [6] (2016). Forward Algorithm, Wikipedia
- [7] (2016). Viterbi Algorithm, Wikipedia
- [8] Murphy, K.P. (2012) Machine Learning - A Probabilistic Perspective, MIT Press
- [9] Barber, D. (2012) Bayesian Reasoning and Machine Learning, Cambridge University Press
- [10] Kuhn, M., Johnson, K. (2013) Applied Predictive Modeling, Springer
- [11] (2016). Q-Learning, Wikipedia
- [12] Mnih, V. et al (2015) "Human-level control through deep reinforcement learning", Nature 518: 529–533
- [13] Brockman, G., Cheung, V., Pettersson, L., Schneider, J., Schulman, J., Tang, J., Zaremba, W. (2016) "OpenAI Gym, arXiv:1606.01540v1 [cs.LG]"
- [14] Bishop, C. (2007) Pattern Recognition and Machine Learning, Springer


