In the last article of the Time Series Analysis series we discussed the importance of serial correlation and why it is extremely useful in the context of quantitative trading.
In this article we will make full use of serial correlation by discussing our first time series models, including some elementary linear stochastic models. In particular we are going to discuss White Noise and Random Walks.
Recapping Our Goal
Before we dive into definitions I want to recap our reasons for studying these models as well as our end goal in learning time series analysis.
Fundamentally we are interested in improving the profitability of our trading algorithms. As quants, we do not rely on "guesswork" or "hunches".
Our approach is to quantify as much as possible, both to remove any emotional involvement from the trading process and to ensure (to the extent possible) repeatability of our trading.
In order to improve the profitability of our trading models, we must make use of statistical techniques to identify consistent behaviour in assets which can be exploited to turn a profit. To find this behaviour we must explore how the properties of the asset prices themselves change in time.
Time Series Analysis helps us to achieve this. It provides us with a robust statistical framework for assessing the behaviour of time series, such as asset prices, in order to help us trade off of this behaviour.
Time Series Analysis provides us with a robust statistical framework for assessing the behaviour of asset prices.
So far we have discussed serial correlation and examined the basic correlation structure of simulated data. In addition we have defined stationarity and considered the second order properties of time series. All of these attributes will aid us in identifying patterns among time series. If you haven't read the previous article on serial correlation, I strongly suggest you do so before continuing with this article.
In the following we are going to examine how we can exploit some of the structure in asset prices that we've identified using time series models.
Time Series Modeling Process
So what is a time series model? Essentially, it is a mathematical model that attempts to "explain" the serial correlation present in a time series.
When we say "explain" what we really mean is once we have "fitted" a model to a time series it should account for some or all of the serial correlation present in the correlogram. That is, by fitting the model to a historical time series, we are reducing the serial correlation and thus "explaining it away".
Our process, as quantitative researchers, is to consider a wide variety of models including their assumptions and their complexity, and then choose a model such that it is the "simplest" that will explain the serial correlation.
Once we have such a model we can use it to predict future values or future behaviour in general. This prediction is obviously extremely useful in quantitative trading.
If we can predict the direction of an asset movement then we have the basis of a trading strategy (allowing for transaction costs, of course!). Also, if we can predict volatility of an asset then we have the basis of another trading strategy or a risk-management approach. This is why we are interested in second order properties, since they give us the means to help us make forecasts.
One question that arises here is "How do we know when we have a good fit for a model?". What criteria do we use to judge which model is best? In fact, there are several! We will be considering these criteria in this article series.
Let's summarise the general process we will be following throughout the series:
- Outline a hypotheis about a particular time series and its behaviour
- Obtain the correlogram of the time series (perhaps using R or Python libraries) and assess its serial correlation
- Use our knowledge of time series models and fit an appropriate model to reduce the serial correlation in the residuals (see below for a definition) of the model and its time series
- Refine the fit until no correlation is present and use mathematical criteria to assess the model fit
- Use the model and its second-order properties to make forecasts about future values
- Assess the accuracy of these forecasts using statistical techniques (such as confusion matrices, ROC curves for classification or regressive metrics such as MSE, MAPE etc)
- Iterate through this process until the accuracy is optimal and then utilise such forecasts to create trading strategies
That is our basic process. The complexity will arise when we consider more advanced models that account for additional serial correlation in our time series.
In this article we are going to consider two of the most basic time series models, namely White Noise and Random Walks. These models will form the basis of more advanced models later so it is essential we understand them well.
However, before we introduce either of these models, we are going to discuss some more abstract concepts that will help us unify our approach to time series models. In particular, we are going to define the Backward Shift Operator and the Difference Operator.
Backward Shift and Difference Operators
The Backward Shift Operator (BSO) and the Difference Operator will allow us to write many different time series models in a particular way that helps us understand how they differ from each other.
Since we will be using the notation of each so frequently, it makes sense to define them now.
Backward Shift Operator
The backward shift operator or lag operator, ${\bf B}$, takes a time series element as an argument and returns the element one time unit previously: ${\bf B} x_t = x_{t-1}$.
Repeated application of the operator allows us to step back $n$ times: ${\bf B}^n x_t = x_{t-n}$.
We will use the BSO to define many of our time series models going forward.
In addition, when we come to study time series models that are non-stationary (that is, their mean and variance can alter with time), we can use a differencing procedure in order to take a non-stationary series and produce a stationary series from it.
Difference Operator
The difference operator, $\nabla$, takes a time series element as an argument and returns the difference between the element and that of one time unit previously: $\nabla x_t = x_t - x_{t-1}$, or $\nabla x_t = (1-{\bf B}) x_t$.
As with the BSO, we can repeatedly apply the difference operator: $\nabla^n = (1-{\bf B})^n$.
Now that we've discussed these abstract operators, let us consider some concrete time series models.
White Noise
Let's begin by trying to motivate the concept of White Noise.
Above, we mentioned that our basic approach was to try fitting models to a time series until the remaining series lacks any serial correlation. This motivates the definition of the residual error series:
Residual Error Series
The residual error series or residuals, $x_t$, is a time series of the difference between an observed value and a predicted value, from a time series model, at a particular time $t$.
If $y_t$ is the observed value and $\hat{y}_t$ is the predicted value, we say: $x_t = y_t - \hat{y}_t$ are the residuals.
The key point is that if our chosen time series model is able to "explain" the serial correlation in the observations, then the residuals themselves are serially uncorrelated.
This means that each element of the serially uncorrelated residual series is an independent realisation from some probability distribution. That is, the residuals themselves are independent and identically distributed (i.i.d.).
Hence, if we are to begin creating time series models that explain away any serial correlation, it seems natural to begin with a process that produces independent random variables from some distribution. This directly leads on to the concept of (discrete) white noise:
Discrete White Noise
Consider a time series $\{w_t: t=1,...n\}$. If the elements of the series, $w_i$, are independent and identically distributed (i.i.d.), with a mean of zero, variance $\sigma^2$ and no serial correlation (i.e. $\text{Cor}(w_i, w_j) \neq 0, \forall i \neq j$) then we say that the time series is discrete white noise (DWN).
In particular, if the values $w_i$ are drawn from a standard normal distribution (i.e. $w_t \sim N(0,\sigma^2)$), then the series is known as Gaussian White Noise.
White Noise is useful in many contexts. In particular, it can be used to simulate a "synthetic" series.
As we've mentioned before, a historical time series is only one observed instance. If we can simulate multiple realisations then we can create "many histories" and thus generate statistics for some of the parameters of particular models. This will help us refine our models and thus increase accuracy in our forecasting.
Now that we've defined Discrete White Noise, we are going to examine some of the attributes of it, including its second order properties and its correlogram.
Second-Order Properties
The second-order properties of DWN are straightforward and follow easily from the actual definition. In particular, the mean of the series is zero and there is no autocorrelation by definition:
\begin{eqnarray} \mu_w = E(w_t) = 0 \end{eqnarray} $$\rho_k = \text{Cor}(w_t, w_{t+k}) = \left\{\begin{aligned} &1 && \text{if} \enspace k = 0 \\ &0 && \text{if} \enspace k \neq 0 \end{aligned} \right.$$Correlogram
We can also plot the correlogram of a DWN using R. Firstly we'll set the random seed to be 1, so that your random draws will be identical to mine. Then we will sample 1000 elements from a normal distribution and plot the autocorrelation:
> set.seed(1)
> acf(rnorm(1000))
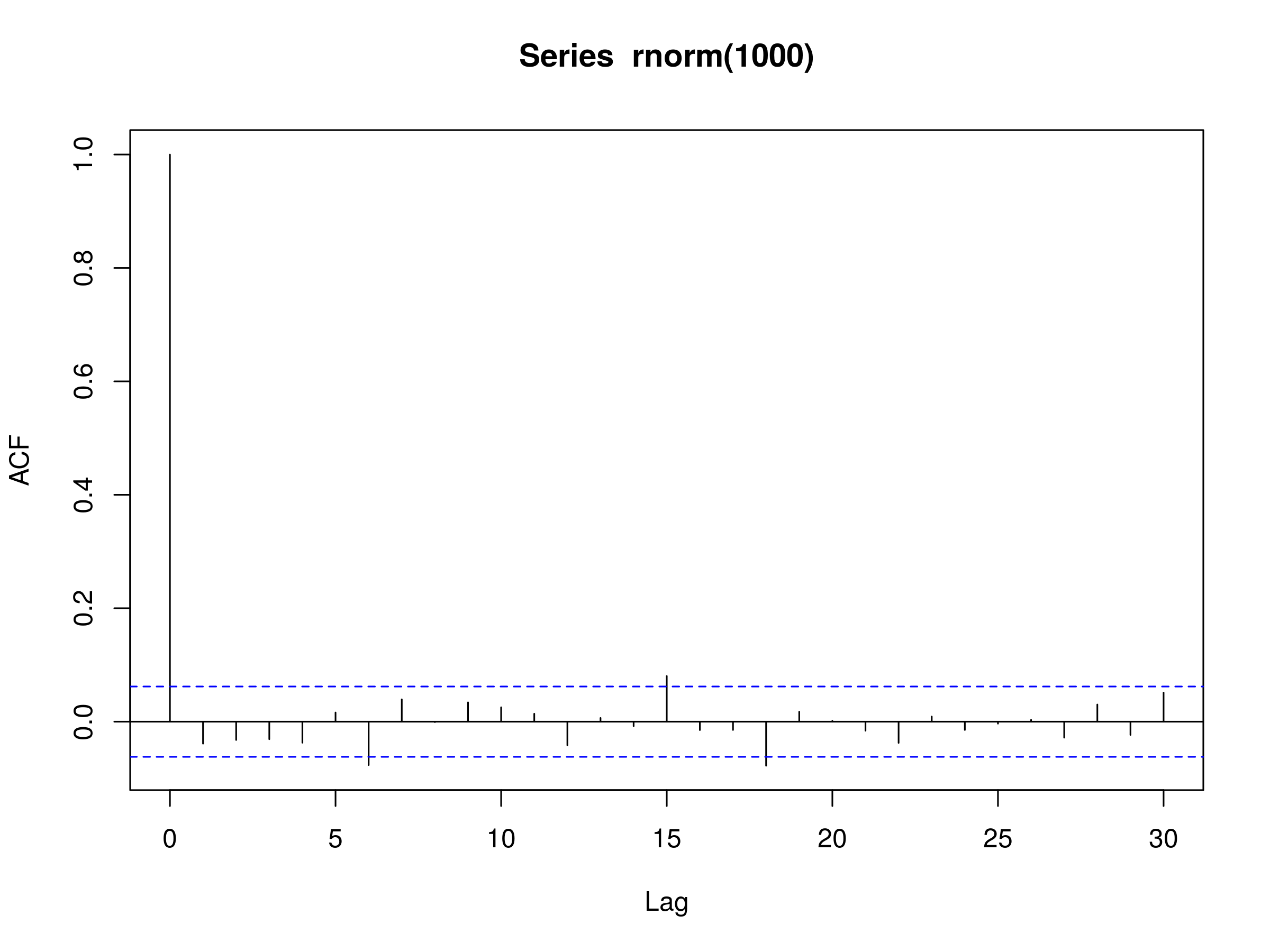 Correlogram of Discrete White Noise
Correlogram of Discrete White Noise
Notice that at $k=6$, $k=15$ and $k=18$, we have three peaks that differ from zero at the 5% level. However, this is to be expected simply due to the variation in sampling from the normal distribution.
Once again, we must be extremely careful in our interpretation of results. In this instance, do we really expect anything physically meaningful to be happening at $k=6$, $k=15$ or $k=18$?
Notice that the DWN model only has a single parameter, namely the variance $\sigma^2$. Thankfully, it is straightforward to estimate the variance with R, we can simply use the var function:
> set.seed(1)
> var(rnorm(1000, mean=0, sd=1))
1.071051
We've specifically highlighted that the normal distribution above has a mean of zero and a standard deviation of 1 (and thus a variance of 1). R calculates the sample variance as 1.071051, which is close to the population value of 1.
The key takeaway with Discrete White Noise is that we use it as a model for the residuals. We are looking to fit other time series models to our observed series, at which point we use DWN as a confirmation that we have eliminated any remaining serial correlation from the residuals and thus have a good model fit.
Now that we have examined DWN we are going to move on to a famous model for (some) financial time series, namely the Random Walk.
Random Walk
A random walk is another time series model where the current observation is equal to the previous observation with a random step up or down. It is formally defined below:
Random Walk
A random walk is a time series model ${x_t}$ such that $x_t = x_{t-1} + w_t$, where $w_t$ is a discrete white noise series.
Recall above that we defined the backward shift operator ${\bf B}$. We can apply the BSO to the random walk:
\begin{eqnarray} x_t = {\bf B} x_t + w_t = x_{t-1} + w_t \end{eqnarray}And stepping back further:
\begin{eqnarray} x_{t-1} = {\bf B} x_{t-1} + w_{t-1} = x_{t-2} + w_{t-1} \end{eqnarray}If we repeat this process until the end of the time series we get:
\begin{eqnarray} x_t = (1 + {\bf B} + {\bf B}^2 + \ldots) w_t \implies x_t = w_t + w_{t-1} + w_{t-2} + \ldots \end{eqnarray}Hence it is clear to see how the random walk is simply the sum of the elements from a discrete white noise series.
Second-Order Properties
The second-order properties of a random walk are a little more interesting than that of discrete white noise. While the mean of a random walk is still zero, the covariance is actually time-dependent. Hence a random walk is non-stationary:
\begin{eqnarray} \mu_x &=& 0 \\ \gamma_k (t) &=& \text{Cov}(x_t, x_{t+k}) = t \sigma^2 \end{eqnarray}In particular, the covariance is equal to the variance multiplied by the time. Hence, as time increases, so does the variance.
What does this mean for random walks? Put simply, it means there is very little point in extrapolating "trends" in them over the long term, as they are literally random walks.
Correlogram
The autocorrelation of a random walk (which is also time-dependent) can be derived as follows:
\begin{eqnarray} \rho_k (t) = \frac{\text{Cov}(x_t, x_{t+k})} {\sqrt{\text{Var}(x_t) \text{Var}(x_{t+k})}} = \frac{t \sigma^2}{\sqrt{t \sigma^2 (t+k) \sigma^2}} = \frac{1}{\sqrt{1+k/t}} \end{eqnarray}Notice that this implies if we are considering a long time series, with short term lags, then we get an autocorrelation that is almost unity. That is, we have extremely high autocorrelation that does not decrease very rapidly as the lag increases. We can simulate such a series using R.
Firstly, we set the seed so that you can replicate my results exactly. Then we create two sequences of random draws ($x$ and $w$), each of which has the same value (as defined by the seed).
We then loop through every element of $x$ and assign it the value of the previous value of $x$ plus the current value of $w$. This gives us the random walk. We then plot the results using type="l" to give us a line plot, rather than a plot of circular points:
> set.seed(4)
> x <- w <- rnorm(1000)
> for (t in 2:1000) x[t] <- x[t-1] + w[t]
> plot(x, type="l")
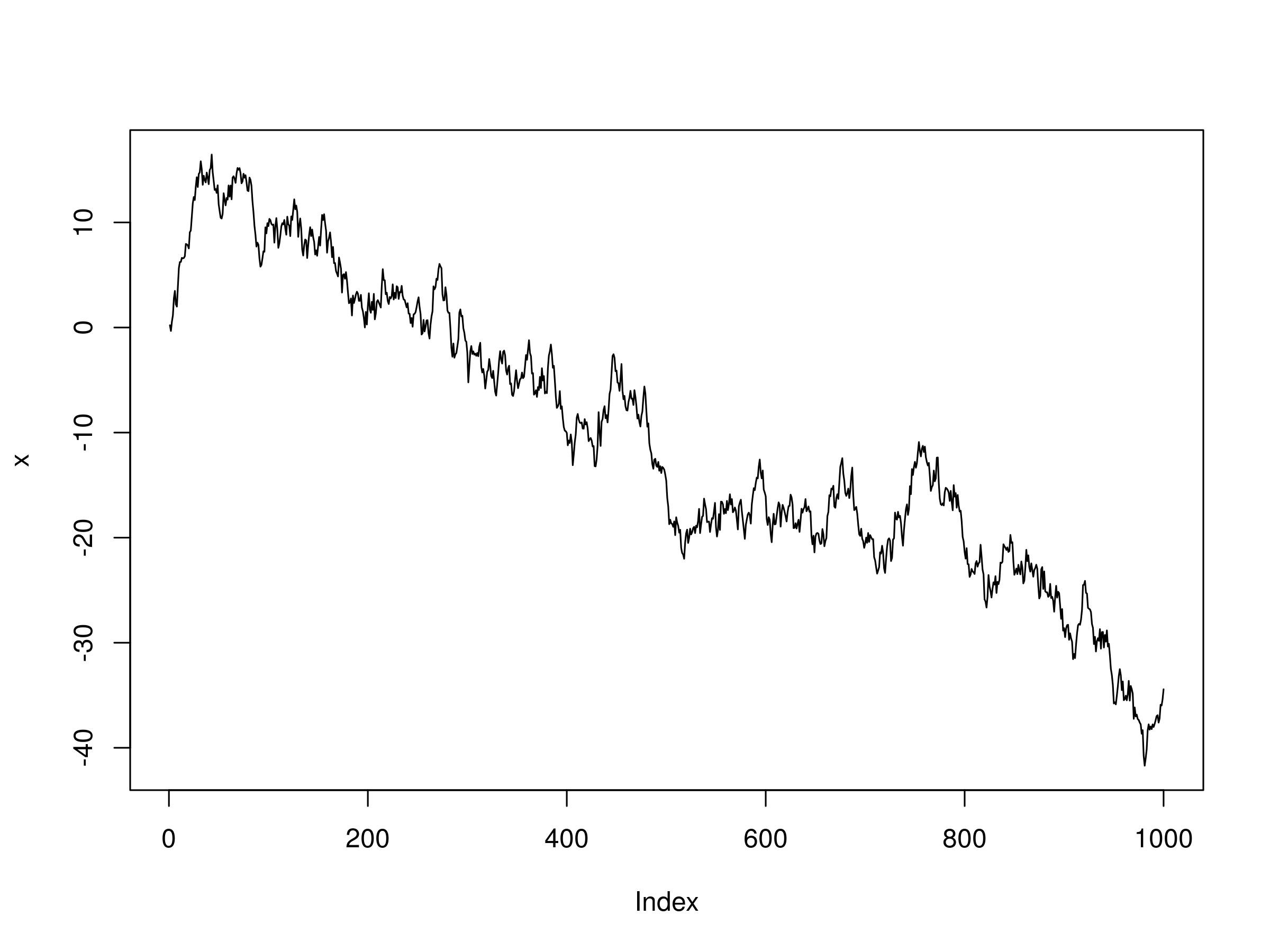 Realisation of a Random Walk with 1000 timesteps
Realisation of a Random Walk with 1000 timesteps
It is simple enough to draw the correlogram too:
> acf(x)
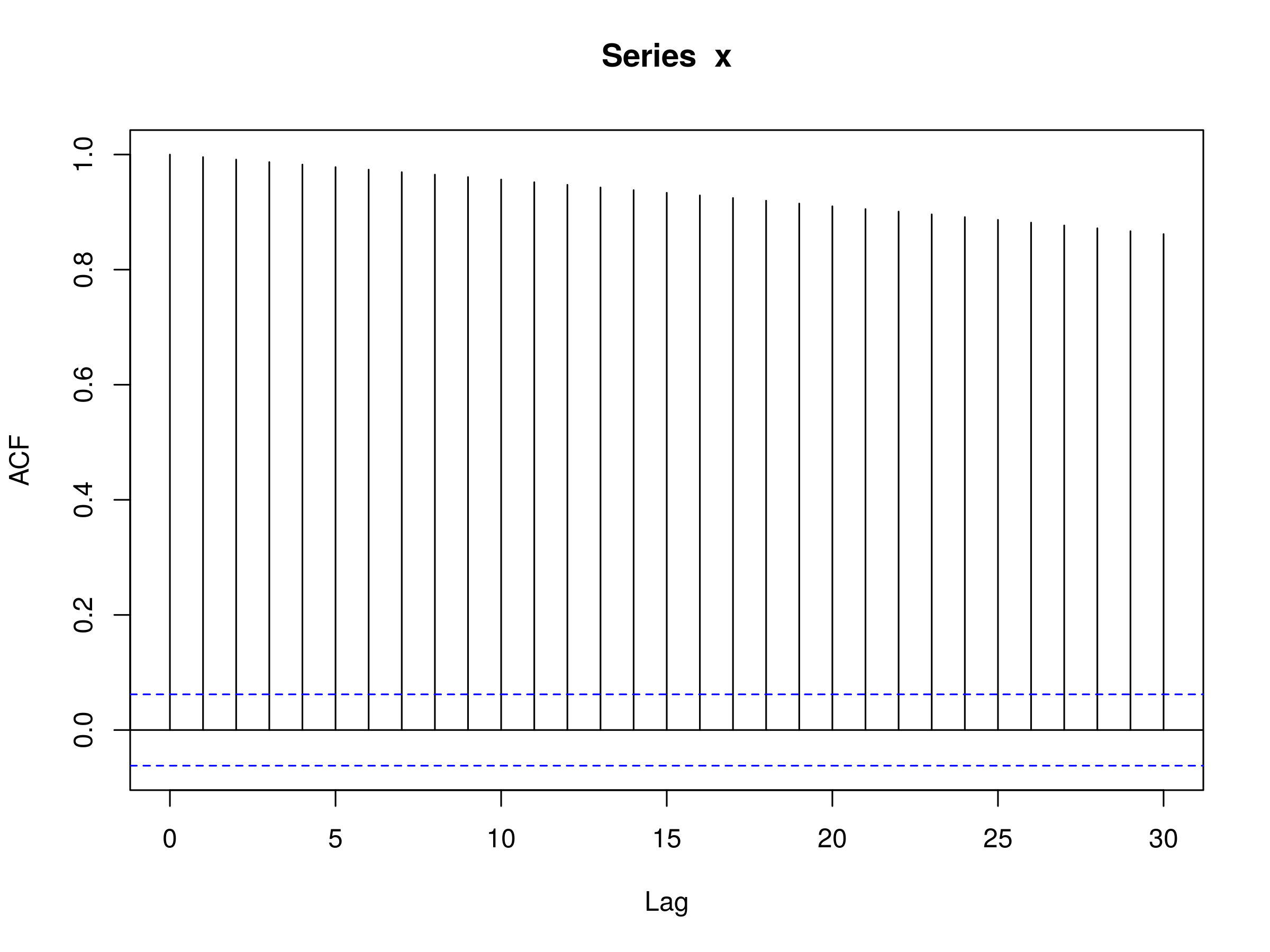 Correlogram of a Random Walk
Correlogram of a Random Walk
Fitting Random Walk Models to Financial Data
We mentioned above and in the previous article that we would try and fit models to data which we have already simulated.
Clearly this is somewhat contrived, as we've simulated the random walk in the first place! However, we're trying to demonstrate the fitting process. In real situations we won't know the underlying generating model for our data, we will only be able to fit models and then assess the correlogram.
We stated that this process was useful because it helps us check that we've correctly implemented the model by trying to ensure that parameter estimates are close to those used in the simulations.
Fitting to Simulated Data
Since we are going to be spending a lot of time fitting models to financial time series, we should get some practice on simulated data first, such that we're well-versed in the process once we start using real data.
We have already simulated a random walk so we may as well use that realisation to see if our proposed model (of a random walk) is accurate.
How can we tell if our proposed random walk model is a good fit for our simulated data? Well, we make use of the definition of a random walk, which is simply that the difference between two neighbouring values is equal to a realisation from a discrete white noise process.
Hence, if we create a series of the differences of elements from our simulated series, we should have a series that resembles discrete white noise!
In R this can be accomplished very straightforwardly using the diff function. Once we have created the difference series, we wish to plot the correlogram and then assess how close this is to discrete white noise:
> acf(diff(x))
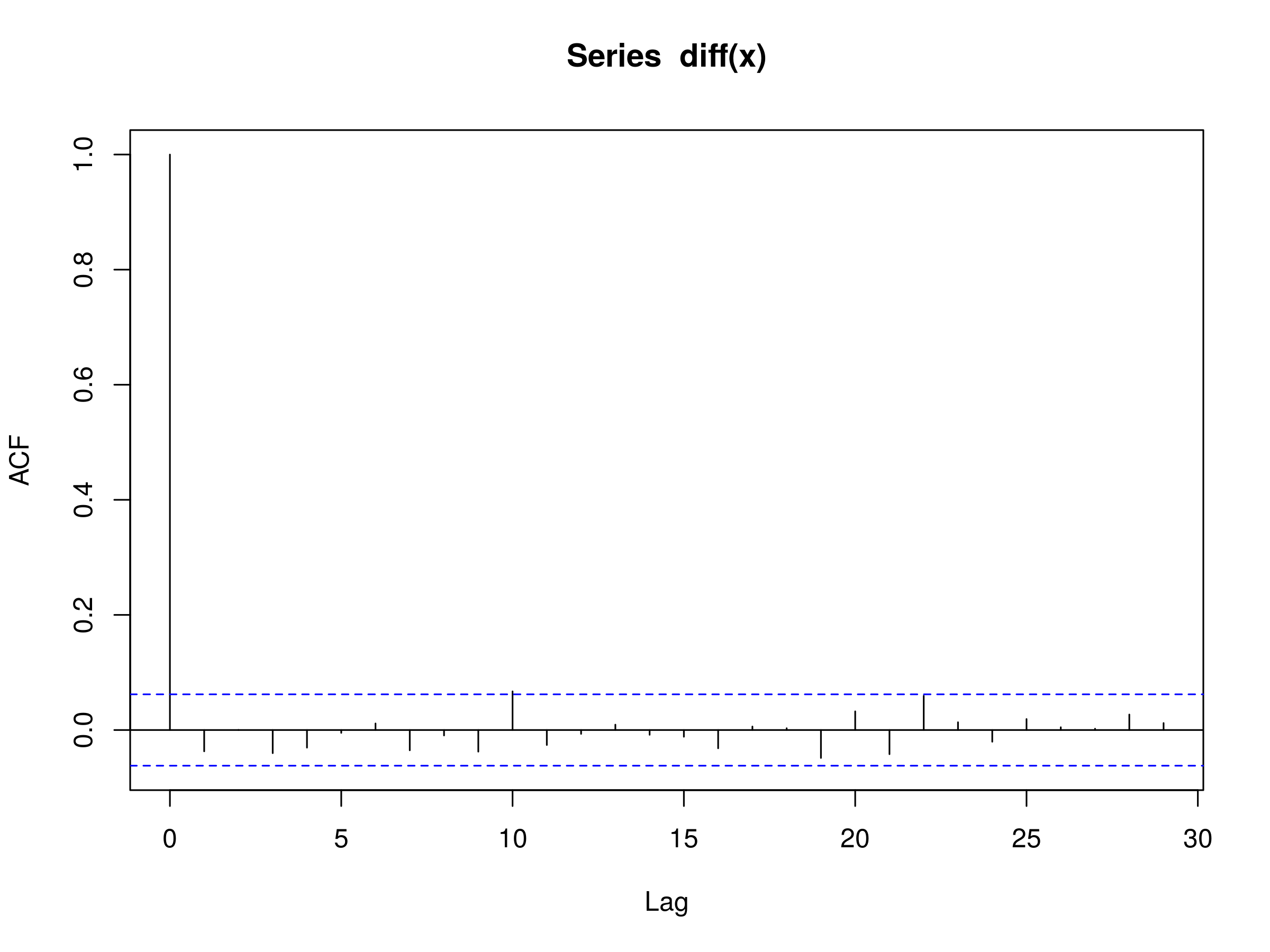 Correlogram of the Difference Series from a Simulated Random Walk
Correlogram of the Difference Series from a Simulated Random Walk
What can we notice from this plot? There is a statistically significant peak at $k=10$, but only marginally. Remember, that we expect to see at least 5% of the peaks be statistically significant, simply due to sampling variation.
Hence we can reasonably state that the the correlogram looks like that of discrete white noise. It implies that the random walk model is a good fit for our simulated data. This is exactly what we should expect, since we simulated a random walk in the first place!
Fitting to Financial Data
Let's now apply our random walk model to some actual financial data. As with the Python library, pandas, we can use the R package quantmod to easily extract financial data from Yahoo Finance.
We are going to see if a random walk model is a good fit for some equities data. In particular, I am going to choose Microsoft (MSFT), but you can experiment with your favourite ticker symbol!
Before we're able to download any of the data, we must install quantmod as it isn't part of the default R installation. Run the following command and select the R package mirror server that is closest to your location:
> install.packages('quantmod')
Once quantmod is installed we can use it to obtain the historical price of MSFT stock:
> require('quantmod')
> getSymbols('MSFT', src='yahoo')
> MSFT
..
..
2015-07-15 45.68 45.89 45.43 45.76 26482000 45.76000
2015-07-16 46.01 46.69 45.97 46.66 25894400 46.66000
2015-07-17 46.55 46.78 46.26 46.62 29262900 46.62000
This will create an object called MSFT (case sensitive!) into the R namespace, which contains the pricing and volume history of MSFT. We're interested in the corporate-action adjusted closing price. We can use the following commands to (respectively) obtain the Open, High, Low, Close, Volume and Adjusted Close prices for the Microsoft stock: Op(MSFT), Hi(MSFT), Lo(MSFT), Cl(MSFT), Vo(MSFT), Ad(MSFT).
Our process will be to take the difference of the Adjusted Close values, omit any missing values, and then run them through the autocorrelation function. When we plot the correlogram we are looking for evidence of discrete white noise, that is, a residuals series that is serially uncorrelated. To carry this out in R, we run the following command:
> acf(diff(Ad(MSFT)), na.action = na.omit)
The latter part (na.action = na.omit) tells the acf function to ignore missing values by omitting them. The output of the acf function is as follows:
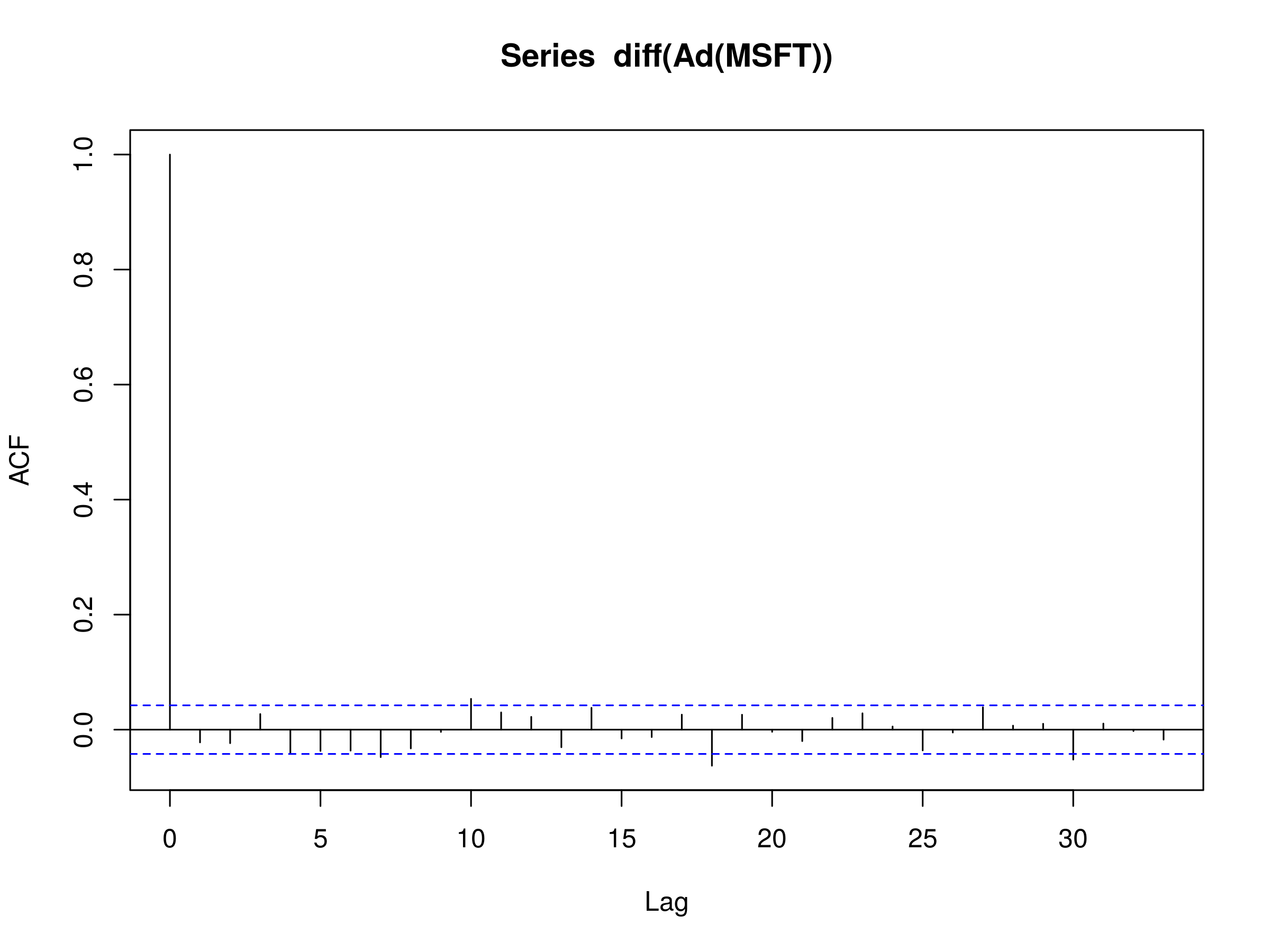 Correlogram of the Difference Series from MSFT Adjusted Close
Correlogram of the Difference Series from MSFT Adjusted Close
We notice that the majority of the lag peaks do not differ from zero at the 5% level. However there are a few that are marginally above. Given that the lags $k_i$ where peaks exist are someway from $k=0$, we could be inclined to think that these are due to stochastic variation and do not represent any physical serial correlation in the series.
Hence we can conclude, with a reasonable degree of certainty, that the adjusted closing prices of MSFT are well approximated by a random walk.
Let's now try the same approach on the S&P500 itself. The Yahoo Finance symbol for the S&P500 index is ^GSPC. Hence, if we enter the following commands into R, we can plot the correlogram of the difference series of the S&P500:
> getSymbols('^GSPC', src='yahoo')
> acf(diff(Ad(GSPC)), na.action = na.omit)
The correlogram is as follows:
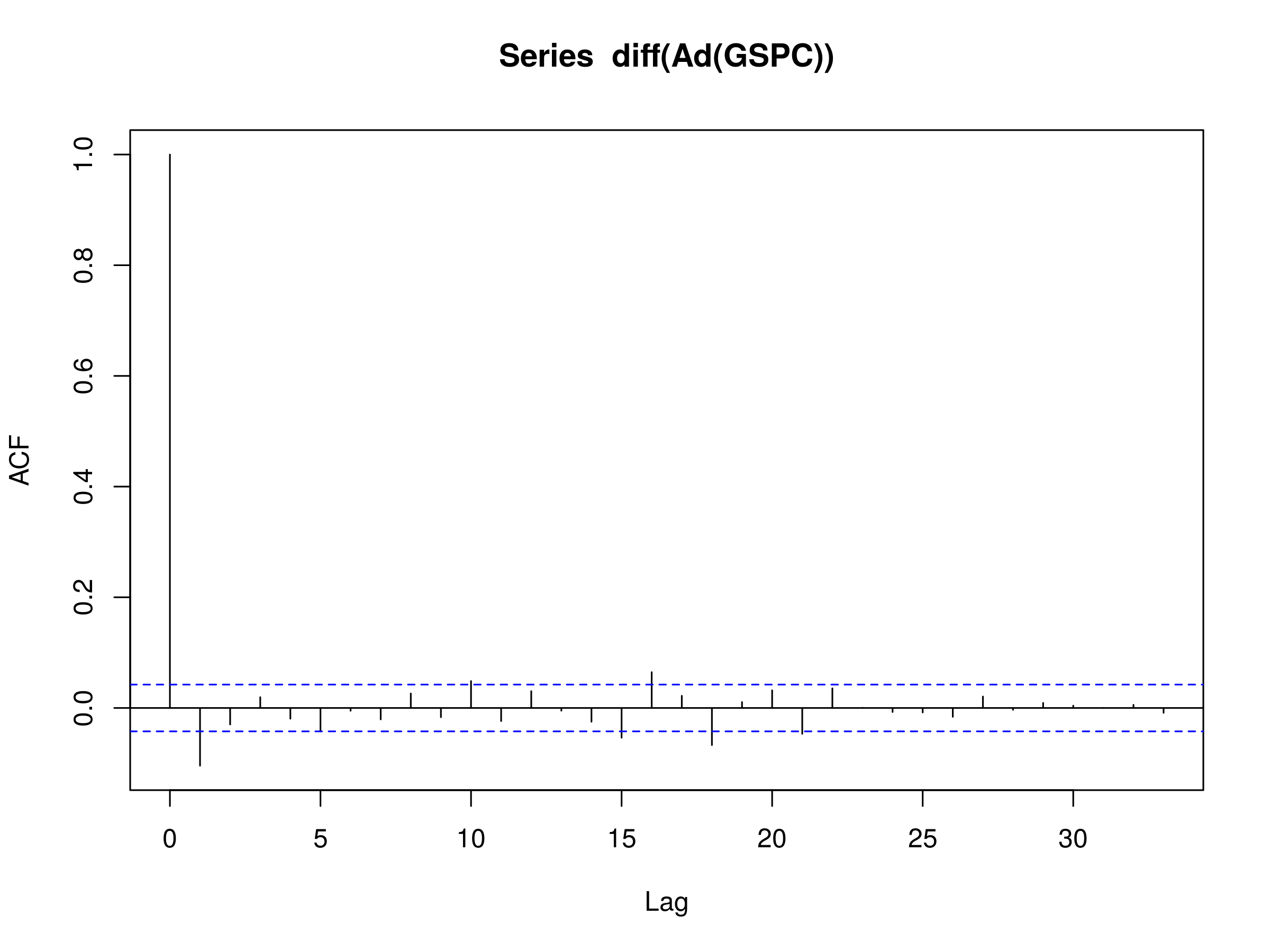 Correlogram of the Difference Series from the S&P500 Adjusted Close
Correlogram of the Difference Series from the S&P500 Adjusted Close
The correlogram here is certainly more interesting. Notice that there is a negative correlation at $k=1$. This is unlikely to be due to random sampling variation.
Notice also that there are peaks at $k=10$, $k=15$, $k=16$, $k=18$ and $k=21$. Although it is harder to justify their existence beyond that of random variation, they may be indicative of a longer-lag process.
Hence it is much harder to justify that a random walk is a good model for the S&P500 Adjusted Close data. This motivates more sophisticated models, namely the Autoregressive Models of Order p, which will be the subject of the next article!


