One of the most problematic areas of quantitative trading is optimising a forecasting strategy to improve its performance.
Seasoned quant traders realise that it is all too easy to generate a strategy with stellar predictive ability on a backtest. However, some backtests can mask the danger of an overfit model, which can lead to drastic underperformance when a strategy is deployed.
In this article we will attempt to find a partial remedy to the problem of an overfit machine learning model using a technique known as cross-validation.
Firstly we will define cross-validation and then describe how it works. Secondly, we will construct a forecasting model using an equity index and then apply two cross-validation methods to this example: the validation set approach and k-fold cross-validation. Finally we will discuss the code for the simulations using Python, Pandas, Matplotlib and Scikit-Learn.
This article is the "spiritual successor" to a previous article I wrote recently on the bias-variance tradeoff. In that article I mentioned that cross-validation was a means of resolving some of the issues brought about by the bias-variance trade-off.
Our goal is to eventually create a set of statistical tools that can be used within a backtesting framework to help us minimise the problem of overfitting a model and thus constrain future losses due to a poorly performing strategy based on such a model.
Overview of Cross-Validation
Recall from the article on the bias-variance tradeoff the definitions of test error and flexibility:
- Test Error - The average error, where the average is across many observations, associated with the predictive performance of a particular statistical model when assessed on new observations that were not used to train the model.
- Flexibility - The degrees of freedom available to the model to "fit" to the training data. A linear regression is very inflexible (it only has two degrees of freedom) whereas a high-degree polynomial is very flexible (and as such can have many degrees of freedom).
With these concepts in mind we can now define cross-validation:
The goal of cross-validation is to estimate the test error associated with a statistical model or select the appropriate level of flexibility for a particular statistical method.
Again, we can recall from the article on the bias-variance tradeoff that the training error associated with a model can vastly underestimate the test error of the model. Cross-validation provides us with the capability to more accurately estimate the test error, which we will never know in practice.
Cross-validation works by holding out particular subsets of the training set in order to use them as test observations. In this article we will discuss the various ways in which such subsets are held out as well as implement the methods using Python on an example forecasting model based on prior historical data.
Forecasting Example
In order to make the following theoretical discussion concrete we will consider the development of a new trading strategy based on the prediction of price levels of an equity index. Since I am based in the UK, I will pick the FTSE100, which contains a weighted grouping of the one hundred largest (by market capitalisation) publicly traded firms on the London Stock Exchange (LSE). Equally we could pick the S&P500 or the DAX.
For this strategy we will simply consider the closing price of the historical daily Open-High-Low-Close (OHLC) bars as predictors and the following day's closing price as the response. Hence we are attempting to predict tomorrow's price using daily historic prices.
An observation will consist of a pair of vectors, $X$ and $y$, which contain the predictor values and the response value respectively. If we consider a daily lag of $p$ days, then $X$ has $p$ components. Each of these components represents the closing price from one day further behind. $X_p$ represents today's closing price (known), while $X_{p-1}$ represents the closing price yesterday, while $X_1$ represents the price $p-1$ days ago.
$Y$ contains only a single value, namely tomorrow's closing price, and is thus a scalar. Hence each observation is a tuple $(X, y)$. We will consider a set of $n$ observations corresponding to $n$ days worth of historical pricing information about the FTSE100.
 The FTSE100 Index - Image Credit: Wikipedia
The FTSE100 Index - Image Credit: Wikipedia
Our goal is to find a statistical model that attempts to predict the price level of the FTSE100 based on the previous days prices. If we were to achieve an accurate prediction, we could use it to generate basic trading signals. This article is primarily interested in the former part of the model, that of the predictive component.
We will use cross-validation in two ways: Firstly to estimate the test error of particular statistical learning methods (i.e. their separate predictive performance), and secondly to select the optimal flexibility of the chosen method in order to minimise the errors associated with bias and variance.
We will now outline the differing ways of carrying out cross-validation, starting with the validation set approach and then finally k-fold cross validation. In each case we will use Pandas and Scikit-Learn to implement these methods.
Validation Set Approach
The validation set approach to cross-validation is very simple to carry out. Essentially we take the set of observations ($n$ days of data) and randomly divide them into two equal halves. One half is known as the training set while the second half is known as the validation set. The model is fit using only the data in the training set, while its test error is estimated using only the validation set.
This is easily recognisable as a technique often used in quantitative trading as a mechanism for assessing predictive performance. However, it is more common to find two-thirds of the data used for the training set, while the remaining third is used for validation. In addition it is more common to retain the ordering of the time series such that the first two-thirds chronologically represents the first two-thirds of the historical data.
What is less common when applying this method is randomising the observations into each of the two separate sets. Even less common is a discussion as to what subtle problems can arises when this is carried out.
Firstly, and especially in situations with limited data, the procedure can lead to a high variance for the estimate of the test error due to the randomisation of the samples. This is a typical "gotcha" when carrying out the validation set approach to cross-validation. It is all too possible to achieve a low test error simply through blind luck on receiving an appropriate random sample split. Hence the true test error (i.e. predictive power) can be significantly underestimated.
Secondly, note that in the 50-50 split of testing/training data we are leaving out half of all observations. Hence we are reducing information that would otherwise be used to train the model. Thus it is likely to perform worse than if we had used all of the observations, including those in the validation set. This leads to a situation where we may actually overestimate the test error for the full data set.
In order to reduce the impact of these issues we will consider a more sophisticated splitting of the data known as k-fold cross validation.
k-Fold Cross Validation
K-fold cross-validation improves upon the validation set approach by dividing the $n$ observations into $k$ mutually exclusive, and approximately equally sized, subsets known as "folds".
The first fold becomes a validation set, while the remaining $k-1$ folds (aggregated together) become the training set. The model is fit on the training set and its test error is estimated on the validation set. This procedure is repeated $k$ times, with each repetition holding out a fold as the validation set, while the remaining $k-1$ are used for training.
This allows an overall test estimate, $\text{CV}_k$, to be calculated that is an average of all the individual mean-squared errors, $\text{MSE}_i$, for each fold:
\begin{eqnarray} \text{CV}_k = \frac{1}{k} \sum^{k}_{i=1} \text{MSE}_i \end{eqnarray}The obvious question that arises at this stage is what value do we choose for $k$? The short answer (based on empirical studies) is to choose $k=5$ or $k=10$. The longer answer to this question relates to both computational expense and, once again, the bias-variance tradeoff.
Leave-One-Out Cross Validation
We can actually choose $k=n$, which means that we fit the model $n$ times, with only a single observation left out for each fitting. This is known as leave-one-out cross-validation (LOOCV). It can be very computationally expensive, particularly if $n$ is large and the model has an expensive fitting procedure.
While LOOCV is beneficial from the point of reducing bias, due to the fact that nearly all of the samples are used for fitting in each case, it actually suffers from the problem of high variance. This is because we are calculating the test error on a single response each time for each observation in the data set.
k-fold cross-validation reduces the variance at the expense of introducing some more bias, due to the fact that some of the observations are not used for training. With $k=5$ or $k=10$ the bias-variance tradeoff is generally optimised.
Python Implementation
We are quite lucky when working with Python and its library ecosystem as much of the "heavy lifting" is done for us. Using Pandas, Scikit-Learn and Matplotlib, we can rapidly create some examples to show the usage and issues surrounding cross-validation.
If you have yet to set up a Python research environment, I highly recommend downloading Spyder. I explain the process in this article.
Obtaining the Data
The first task is to obtain the data and put it in a format we can use. I've actually carried out this procedure in a previous article, but it was some time ago and I feel it is worthwhile to try and have these articles as self-contained as possible! Hence, you can use the following code to obtain historical data from any financial time series available on Yahoo Finance, as well as their associated daily predictor lag values:
import datetime
import numpy as np
import pandas as pd
import sklearn
from pandas.io.data import DataReader
def create_lagged_series(symbol, start_date, end_date, lags=5):
"""
This creates a pandas DataFrame that stores the percentage returns of the
adjusted closing value of a stock obtained from Yahoo Finance, along with
a number of lagged returns from the prior trading days (lags defaults to 5 days).
Trading volume, as well as the Direction from the previous day, are also included.
"""
# Obtain stock information from Yahoo Finance
ts = DataReader(symbol, "yahoo", start_date-datetime.timedelta(days=365), end_date)
# Create the new lagged DataFrame
tslag = pd.DataFrame(index=ts.index)
tslag["Today"] = ts["Adj Close"]
tslag["Volume"] = ts["Volume"]
# Create the shifted lag series of prior trading period close values
for i in xrange(0,lags):
tslag["Lag%s" % str(i+1)] = ts["Adj Close"].shift(i+1)
# Create the returns DataFrame
tsret = pd.DataFrame(index=tslag.index)
tsret["Volume"] = tslag["Volume"]
tsret["Today"] = tslag["Today"].pct_change()*100.0
# If any of the values of percentage returns equal zero, set them to
# a small number (stops issues with QDA model in scikit-learn)
for i,x in enumerate(tsret["Today"]):
if (abs(x) < 0.0001):
tsret["Today"][i] = 0.0001
# Create the lagged percentage returns columns
for i in xrange(0,lags):
tsret["Lag%s" % str(i+1)] = tslag["Lag%s" % str(i+1)].pct_change()*100.0
# Create the "Direction" column (+1 or -1) indicating an up/down day
tsret["Direction"] = np.sign(tsret["Today"])
tsret = tsret[tsret.index >= start_date]
return tsret
Note that we are not storing the direct close price values in the "Today" or "Lag" columns. Instead we are storing the close-to-close percentage return from the previous day.
We need to obtain the data for the FTSE100 daily prices along some suitable time frame. I have chosen Jan 1st 2004 to Dec 31st 2004. However this is an arbitrary choice. You can adjust the time frame as you see fit. To obtain the data and place it into a Pandas DataFrame called ftse_lags we can use the following code:
if __name__ == "__main__":
symbol = "^FTSE"
start_date = datetime.datetime(2004, 1, 1)
end_date = datetime.datetime(2004, 12, 31)
ftse_lags = create_lagged_series(symbol, start_date, end_date, lags=5)
At this stage we have the necessary data to begin creating a set of statistical machine learning models.
Validation Set Approach
Now that we have the financial data we need to create a set of predictive regression models we can use the above cross-validation methods to obtain estimates for the test error.
The first task is to import the models from Scikit-Learn. We will choose a Linear Regression model with polynomial features. This provides us with the ability to choose varying degrees of flexibility simply by increasing the degree of the features' polynomial order. Initially we are going to consider the validation set approach to cross validation.
Scikit-Learn provides a validation set approach via the train_test_split method found in the cross_validation module. We will also need to import the KFold method for k-fold cross validation later, as well as the linear regression model itself. We need to import the MSE calculation as well as Pipeline and PolynomialFeatures. The latter two allow us to easily create a set of polynomial feature linear regression models with minimal additional coding:
..
from sklearn.cross_validation import train_test_split, KFold
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
..
Once the modules are imported we can create a FTSE DataFrame that uses five of the prior lagging days returns as predictors. We can then create ten separate random splittings of the data into a training and validation set.
Finally, for multiple degrees of the polynomial features of the linear regression, we can calculate the test error. This provides us with ten separate test error curves, each value of which shows the test MSE for a differing degree of polynomial kernel:
..
..
def validation_set_poly(random_seeds, degrees, X, y):
"""
Use the train_test_split method to create a
training set and a validation set (50% in each)
using "random_seeds" separate random samplings over
linear regression models of varying flexibility
"""
sample_dict = dict([("seed_%s" % i,[]) for i in range(1, random_seeds+1)])
# Loop over each random splitting into a train-test split
for i in range(1, random_seeds+1):
print "Random: %s" % i
# Increase degree of linear regression polynomial order
for d in range(1, degrees+1):
print "Degree: %s" % d
# Create the model, split the sets and fit it
polynomial_features = PolynomialFeatures(
degree=d, include_bias=False
)
linear_regression = LinearRegression()
model = Pipeline([
("polynomial_features", polynomial_features),
("linear_regression", linear_regression)
])
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.5, random_state=i
)
model.fit(X_train, y_train)
# Calculate the test MSE and append to the
# dictionary of all test curves
y_pred = model.predict(X_test)
test_mse = mean_squared_error(y_test, y_pred)
sample_dict["seed_%s" % i].append(test_mse)
# Convert these lists into numpy arrays to perform averaging
sample_dict["seed_%s" % i] = np.array(sample_dict["seed_%s" % i])
# Create the "average test MSE" series by averaging the
# test MSE for each degree of the linear regression model,
# across all random samples
sample_dict["avg"] = np.zeros(degrees)
for i in range(1, random_seeds+1):
sample_dict["avg"] += sample_dict["seed_%s" % i]
sample_dict["avg"] /= float(random_seeds)
return sample_dict
..
..
We can use Matplotlib to plot this data. We need to import pylab and then create a function to plot the test error curves:
..
import pylab as plt
..
..
def plot_test_error_curves_vs(sample_dict, random_seeds, degrees):
fig, ax = plt.subplots()
ds = range(1, degrees+1)
for i in range(1, random_seeds+1):
ax.plot(ds, sample_dict["seed_%s" % i], lw=2, label='Test MSE - Sample %s' % i)
ax.plot(ds, sample_dict["avg"], linestyle='--', color="black", lw=3, label='Avg Test MSE')
ax.legend(loc=0)
ax.set_xlabel('Degree of Polynomial Fit')
ax.set_ylabel('Mean Squared Error')
ax.set_ylim([0.0, 4.0])
fig.set_facecolor('white')
plt.show()
..
..
We have selected the degree of our polynomial features to vary between $d=1$ to $d=3$, thus providing us with up to cubic order in our features. Figure 1 below displays the ten different random splittings of the training and testing data along with the average test MSE (the black dashed line):
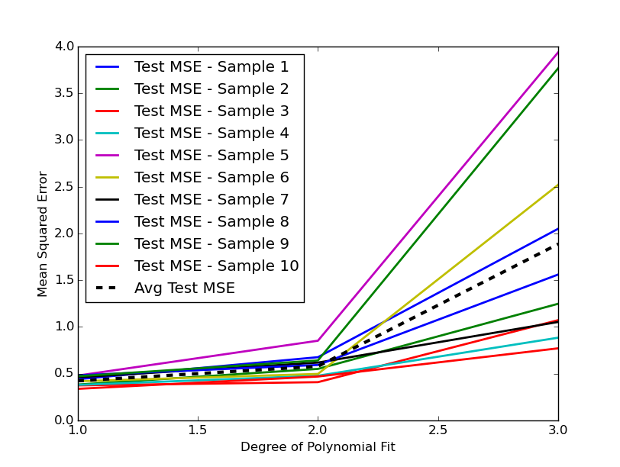 Figure 1 - Test MSE curves for multiple training-validation splits for a Linear Regression with polynomial features of increasing degree.
Figure 1 - Test MSE curves for multiple training-validation splits for a Linear Regression with polynomial features of increasing degree.
It is immediately apparent how much variation there is across different random splits into a training and validation set. Since there is not a great deal of predictive signal in using previous days historical close prices of the FTSE100, we see that as the degree of the polynomial features increases the test MSE actually increases.
In addition it is clear that the validation set suffers from high variance. The average test MSE for the validation set approach on the degree $d=3$ model is approximately 1.9.
In order to minimise this issue we will now implement k-fold cross-validation on the same FTSE100 dataset.
k-Fold Cross Validation
Since we have already taken care of the imports above, I will simply outline the new functions for carrying out k-fold cross-validation. They are almost identical to the functions used for the training-test split. However, we need to use the KFold object to iterate over $k$ "folds".
In particular the KFold object provides an iterator that allows us to correctly index the samples in the data set and create separate training/test folds. I have chosen $k=10$ for this example.
As with the validation set approach, we create a pipeline of polynomial feature transformation and then apply a linear regression model. We then calculate the test MSE and construct separate test MSE curves for each fold. Finally, we create an average MSE curve across folds:
..
..
def k_fold_cross_val_poly(folds, degrees, X, y):
n = len(X)
kf = KFold(n, n_folds=folds)
kf_dict = dict([("fold_%s" % i,[]) for i in range(1, folds+1)])
fold = 0
for train_index, test_index in kf:
fold += 1
print "Fold: %s" % fold
X_train, X_test = X.ix[train_index], X.ix[test_index]
y_train, y_test = y.ix[train_index], y.ix[test_index]
# Increase degree of linear regression polynomial order
for d in range(1, degrees+1):
print "Degree: %s" % d
# Create the model and fit it
polynomial_features = PolynomialFeatures(
degree=d, include_bias=False
)
linear_regression = LinearRegression()
model = Pipeline([
("polynomial_features", polynomial_features),
("linear_regression", linear_regression)
])
model.fit(X_train, y_train)
# Calculate the test MSE and append to the
# dictionary of all test curves
y_pred = model.predict(X_test)
test_mse = mean_squared_error(y_test, y_pred)
kf_dict["fold_%s" % fold].append(test_mse)
# Convert these lists into numpy arrays to perform averaging
kf_dict["fold_%s" % fold] = np.array(kf_dict["fold_%s" % fold])
# Create the "average test MSE" series by averaging the
# test MSE for each degree of the linear regression model,
# across each of the k folds.
kf_dict["avg"] = np.zeros(degrees)
for i in range(1, folds+1):
kf_dict["avg"] += kf_dict["fold_%s" % i]
kf_dict["avg"] /= float(folds)
return kf_dict
..
..
We can plot these curves with the following function:
..
..
def plot_test_error_curves_kf(kf_dict, folds, degrees):
fig, ax = plt.subplots()
ds = range(1, degrees+1)
for i in range(1, folds+1):
ax.plot(ds, kf_dict["fold_%s" % i], lw=2, label='Test MSE - Fold %s' % i)
ax.plot(ds, kf_dict["avg"], linestyle='--', color="black", lw=3, label='Avg Test MSE')
ax.legend(loc=0)
ax.set_xlabel('Degree of Polynomial Fit')
ax.set_ylabel('Mean Squared Error')
ax.set_ylim([0.0, 4.0])
fig.set_facecolor('white')
plt.show()
..
..
The output is given in Figure 2 below:
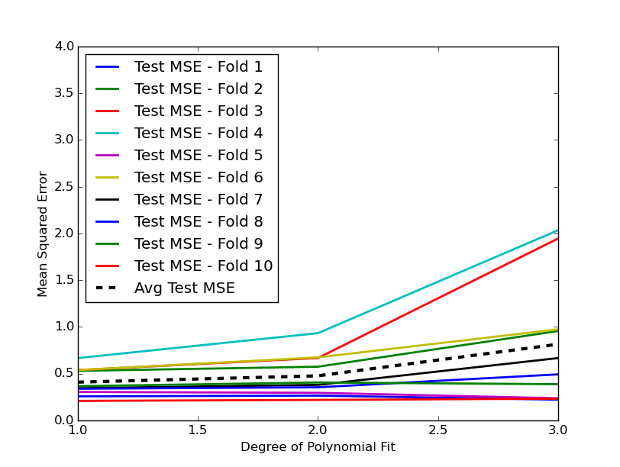 Figure 2 - Test MSE curves for multiple k-fold cross-validation folds for a Linear Regression with polynomial features of increasing degree.
Figure 2 - Test MSE curves for multiple k-fold cross-validation folds for a Linear Regression with polynomial features of increasing degree.
Notice that the variation among the error curves is much lower than for the validation set approach. This is the desired effect of carrying out cross-validation. In particular, at $d=3$ we have a reduced average test error of around 0.8.
Cross-validation generally provides a much better estimate of the true test MSE, at the expense of some slight bias. This is usually an acceptable trade-off in machine learning applications.
In future articles we will consider alternative resampling approaches including the Bootstrap, Bootstrap Aggregation ("Bagging") and Boosting. These are more sophisticated techniques that will help us better select our models and (hopefully) reduce our errors even further.
Full Python Code
The full Python code for cross_validation.py is given below:
import datetime
import pprint
import numpy as np
import pandas as pd
from pandas.io.data import DataReader
import pylab as plt
import sklearn
from sklearn.cross_validation import train_test_split, KFold
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
def create_lagged_series(symbol, start_date, end_date, lags=5):
"""
This creates a pandas DataFrame that stores the percentage returns of the
adjusted closing value of a stock obtained from Yahoo Finance, along with
a number of lagged returns from the prior trading days (lags defaults to 5 days).
Trading volume, as well as the Direction from the previous day, are also included.
"""
# Obtain stock information from Yahoo Finance
ts = DataReader(symbol, "yahoo", start_date-datetime.timedelta(days=365), end_date)
# Create the new lagged DataFrame
tslag = pd.DataFrame(index=ts.index)
tslag["Today"] = ts["Adj Close"]
tslag["Volume"] = ts["Volume"]
# Create the shifted lag series of prior trading period close values
for i in xrange(0,lags):
tslag["Lag%s" % str(i+1)] = ts["Adj Close"].shift(i+1)
# Create the returns DataFrame
tsret = pd.DataFrame(index=tslag.index)
tsret["Volume"] = tslag["Volume"]
tsret["Today"] = tslag["Today"].pct_change()*100.0
# If any of the values of percentage returns equal zero, set them to
# a small number (stops issues with QDA model in scikit-learn)
for i,x in enumerate(tsret["Today"]):
if (abs(x) < 0.0001):
tsret["Today"][i] = 0.0001
# Create the lagged percentage returns columns
for i in xrange(0,lags):
tsret["Lag%s" % str(i+1)] = tslag["Lag%s" % str(i+1)].pct_change()*100.0
# Create the "Direction" column (+1 or -1) indicating an up/down day
tsret["Direction"] = np.sign(tsret["Today"])
tsret = tsret[tsret.index >= start_date]
return tsret
def validation_set_poly(random_seeds, degrees, X, y):
"""
Use the train_test_split method to create a
training set and a validation set (50% in each)
using "random_seeds" separate random samplings over
linear regression models of varying flexibility
"""
sample_dict = dict([("seed_%s" % i,[]) for i in range(1, random_seeds+1)])
# Loop over each random splitting into a train-test split
for i in range(1, random_seeds+1):
print "Random: %s" % i
# Increase degree of linear regression polynomial order
for d in range(1, degrees+1):
print "Degree: %s" % d
# Create the model, split the sets and fit it
polynomial_features = PolynomialFeatures(
degree=d, include_bias=False
)
linear_regression = LinearRegression()
model = Pipeline([
("polynomial_features", polynomial_features),
("linear_regression", linear_regression)
])
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.5, random_state=i
)
model.fit(X_train, y_train)
# Calculate the test MSE and append to the
# dictionary of all test curves
y_pred = model.predict(X_test)
test_mse = mean_squared_error(y_test, y_pred)
sample_dict["seed_%s" % i].append(test_mse)
# Convert these lists into numpy arrays to perform averaging
sample_dict["seed_%s" % i] = np.array(sample_dict["seed_%s" % i])
# Create the "average test MSE" series by averaging the
# test MSE for each degree of the linear regression model,
# across all random samples
sample_dict["avg"] = np.zeros(degrees)
for i in range(1, random_seeds+1):
sample_dict["avg"] += sample_dict["seed_%s" % i]
sample_dict["avg"] /= float(random_seeds)
return sample_dict
def k_fold_cross_val_poly(folds, degrees, X, y):
n = len(X)
kf = KFold(n, n_folds=folds)
kf_dict = dict([("fold_%s" % i,[]) for i in range(1, folds+1)])
fold = 0
for train_index, test_index in kf:
fold += 1
print "Fold: %s" % fold
X_train, X_test = X.ix[train_index], X.ix[test_index]
y_train, y_test = y.ix[train_index], y.ix[test_index]
# Increase degree of linear regression polynomial order
for d in range(1, degrees+1):
print "Degree: %s" % d
# Create the model and fit it
polynomial_features = PolynomialFeatures(
degree=d, include_bias=False
)
linear_regression = LinearRegression()
model = Pipeline([
("polynomial_features", polynomial_features),
("linear_regression", linear_regression)
])
model.fit(X_train, y_train)
# Calculate the test MSE and append to the
# dictionary of all test curves
y_pred = model.predict(X_test)
test_mse = mean_squared_error(y_test, y_pred)
kf_dict["fold_%s" % fold].append(test_mse)
# Convert these lists into numpy arrays to perform averaging
kf_dict["fold_%s" % fold] = np.array(kf_dict["fold_%s" % fold])
# Create the "average test MSE" series by averaging the
# test MSE for each degree of the linear regression model,
# across each of the k folds.
kf_dict["avg"] = np.zeros(degrees)
for i in range(1, folds+1):
kf_dict["avg"] += kf_dict["fold_%s" % i]
kf_dict["avg"] /= float(folds)
return kf_dict
def plot_test_error_curves_vs(sample_dict, random_seeds, degrees):
fig, ax = plt.subplots()
ds = range(1, degrees+1)
for i in range(1, random_seeds+1):
ax.plot(ds, sample_dict["seed_%s" % i], lw=2, label='Test MSE - Sample %s' % i)
ax.plot(ds, sample_dict["avg"], linestyle='--', color="black", lw=3, label='Avg Test MSE')
ax.legend(loc=0)
ax.set_xlabel('Degree of Polynomial Fit')
ax.set_ylabel('Mean Squared Error')
ax.set_ylim([0.0, 4.0])
fig.set_facecolor('white')
plt.show()
def plot_test_error_curves_kf(kf_dict, folds, degrees):
fig, ax = plt.subplots()
ds = range(1, degrees+1)
for i in range(1, folds+1):
ax.plot(ds, kf_dict["fold_%s" % i], lw=2, label='Test MSE - Fold %s' % i)
ax.plot(ds, kf_dict["avg"], linestyle='--', color="black", lw=3, label='Avg Test MSE')
ax.legend(loc=0)
ax.set_xlabel('Degree of Polynomial Fit')
ax.set_ylabel('Mean Squared Error')
ax.set_ylim([0.0, 4.0])
fig.set_facecolor('white')
plt.show()
if __name__ == "__main__":
symbol = "^FTSE"
start_date = datetime.datetime(2004, 1, 1)
end_date = datetime.datetime(2004, 12, 31)
ftse_lags = create_lagged_series(symbol, start_date, end_date, lags=5)
# Use all twenty prior two days of returns as
# predictor values, with "Today" as the response
X = ftse_lags[[
"Lag1", "Lag2", "Lag3", "Lag4", "Lag5",
#"Lag6", "Lag7", "Lag8", "Lag9", "Lag10",
#"Lag11", "Lag12", "Lag13", "Lag14", "Lag15",
#"Lag16", "Lag17", "Lag18", "Lag19", "Lag20"
]]
y = ftse_lags["Today"]
degrees = 3
# Plot the test error curves for validation set
random_seeds = 10
sample_dict_val = validation_set_poly(random_seeds, degrees, X, y)
plot_test_error_curves_vs(sample_dict_val, random_seeds, degrees)
# Plot the test error curves for k-fold CV set
folds = 10
kf_dict = k_fold_cross_val_poly(folds, degrees, X, y)
plot_test_error_curves_kf(kf_dict, folds, degrees)



{kind=link}