In my previous article I explained how to install CUDA on OS X. Now it's time to start coding. However, I don't want to merely show you some piece of "ready-made" code. I would also like to also explain to you the basic concepts behind parallel programming and, specifically, GPU programming. Hence, in this article and in the following ones, I will pair some key theory with code examples.
Today I will explain how GPUs work and show you how to turn theory into practice through a basic vector addition script. I won't dwell upon theory too much but we need to know some basic parallel computing ideas before going ahead with some programming.
So let's start with the one million dollar question: Why parallelise? Well, I provided a motivating example in my previous article via the story about removal vans. Now I would like to give you some numbers to think about, as well as introducing the vector addition problem that we'll consider later on in this article.
We want to sum two one-dimensional vectors, A and B, containing 512 cells (numbers) each, with the result contained in a third vector, named C. This is considered by some to be the "Hello World" example for CUDA.
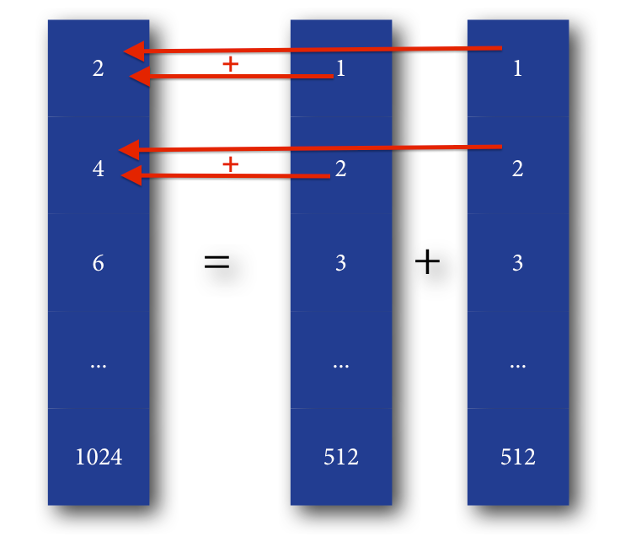
Vector addition
Serial Process
Let's say we have a fast CPU that can perform a simple addition in 1ns (nanosecond). We have two one-dimensional vectors with 512 elements each, so the CPU will compute the first addition, and then the second addition, and the third, and so on until it computes the 512th addition. Assuming that every other aspect of the calculation requires no time then it would take 512ns to get our vector, C, completely filled. Actually, we are making a restrictive assumption dealing with only 512 elements, but it is fine for large numbers. Later I'll go into more details.
Parallel Process
Now let's have a try with a GPU. Modern GPUs can have thousands of slower processors, so, as we have only 512 additions to do, we can do them all in parallel. As those processors are slower, let's assume that each will compute one addition in 10ns. But they are all doing it simultaneously, so the total time spent calculating our C vector is 10ns!
In conclusion, we can see that parallel computing needs more time to perform a single task, but can efficiently manage to do thousands of them at a time. So it's optimised for throughput. Otherwise, serial programming is far more efficient for the single task (in our example ten times faster!), and as such is optimised for latency.
This means that there isn't a single best approach, but we can choose the best method for each task we might need to carry out.
Basic GPU computing
There are two main types of parallelism: task parallelism and data parallelism. Sticking with our vector addition, let's say we have to sum multiple vectors. In this case, each addition C=A+B is a task. So, having vectors with 512 elements, we have to perform 512 operations on each task. Of course, we can parallelise both of them, and the latter is data parallelism. In this article I'll show you how to perform the latter, but I'll cover task parallelism in future.
The basic structure of a parallel program, as shown in the following picture, is composed of a serial part, a parallel part and then a final serial part. Also, communication between the CPU (host) and the GPU (device) is needed for memory allocation and data transfer.
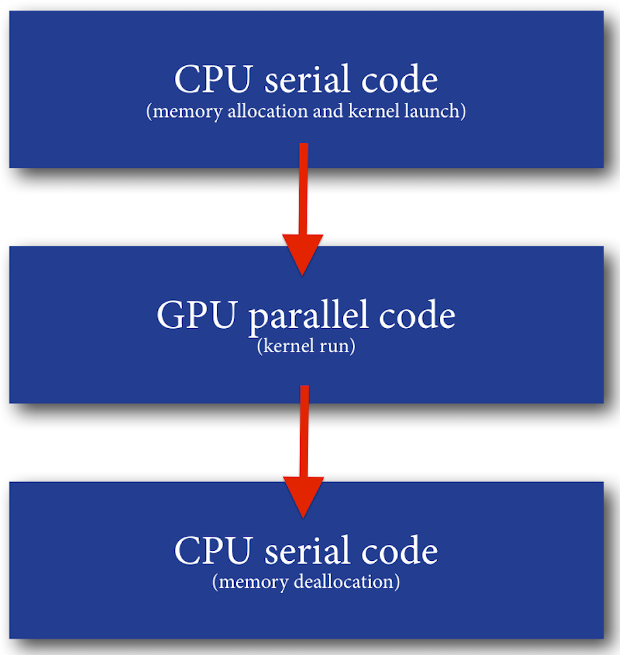
Code flow
When you launch a function which executes operations in parallel, you're launching what is known as a kernel. Each kernel has a task to complete and to do so it makes use of what are known as threads. We can consider a thread as a subtask (in our case, a single addition), which are grouped along with other threads in blocks. Blocks are grouped in grids and each block can contain up to 1024 threads (or 512 on older GPUs). We can launch in parallel as many blocks as our GPU can support. Also note that for maximising hardware efficiency the number of threads in a block should be a multiple of 32.
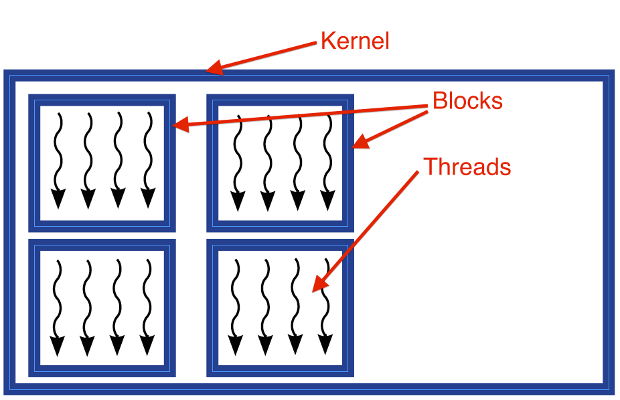
Kernel structure
Vector addition
What follows is a simple vector addition script (the complete code is at the end of this page). As we are concentrating primarily on the code, I'll show you how to carry this out using NVIDIA's Nsight environment (Eclipse edition). I believe this is a very useful resource for those who do not have terminal or command line experience. Those who have experience will not have trouble considering other IDEs!
In general, CUDA scripts can be coded in only one file (with extension .cu) but, for the sake of generality, I prefer to split kernel code and serial code in distinct files (C++ and CUDA, respectively). I find this very useful for more complex programs and I believe it's a good way to start "thinking in parallel".
The first thing we have to do is make a new project. So open Nsight, click on New>CUDA C/C++ Project, type the project name and select CUDA Runtime Project, CUDA toolkit 6.0.
New project on File menu
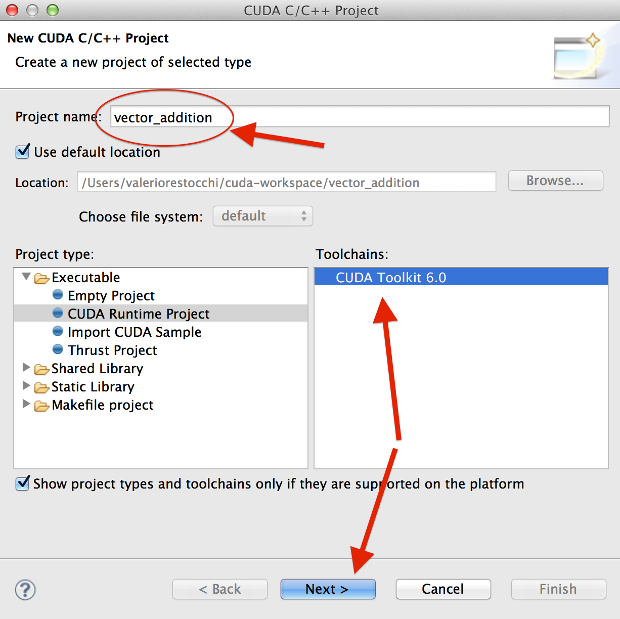
New Project window
Now you have to choose you source folder name ("src" is fine) and check the box that matches your GPU compute capability. Mine is 3.0, so I checked only 3.0 on both of the lines.
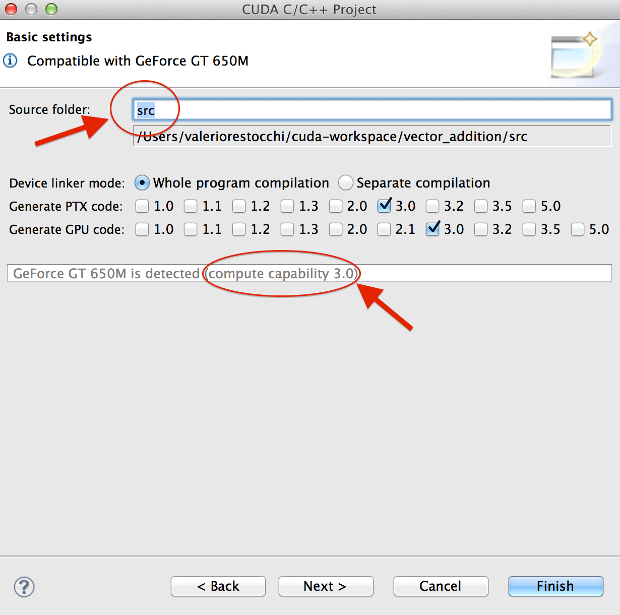
Select source folder and compute capability
Now you should have a folder with the selected name, including two subfolders, "Includes" and "src". As we selected the Runtime Project you'll also have a "vector_addition.cu" file. Delete it by right-clicking and choosing Delete, as we don't need it.
Just a step more: Select this folder and click on the New Source File button at the top-left. As I said, I prefer to split CPU and GPU parts, so, after the name, also type ".cpp".

New file button
You should have your .cpp file in your vector_addition/src folder. Open it and let's start coding!
Includes and variables declarationFirst, let's include some libraries we'll use later in this script. So type
#include <math.h>
#include <time.h>
#include <iostream>
#include <stdexcept>
#include "cuda_runtime.h"
#include "kernel.h"
and then declare the variables we need
// declare the vectors' number of elements and their size in bytes
static const int n_el = 512;
static const size_t size = n_el * sizeof(float);
int main() {
// declare and allocate input vectors h_A and h_B in the host (CPU) memory
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
// declare device vectors in the device (GPU) memory
float *d_A,*d_B,*d_C;
h_A and h_B are the vectors we want to sum into h_C, while d_C is the vector in which we'll store the result. Note that I used the prefix h_ or d_on every variable name. This is a good habit to discern host (CPU) variables from device (GPU) ones. Of course this is just my favourite form, but you may encounter programmers who prefer something like Host_a, a_host, a_h etc. Those are all equivalent conventions, so you can choose the one with which you're most comfortable. You can also just name them a, b, c, but always remember which variable to use within the host and which one on the device, or you will soon get into trouble!
Now we can initialise the vectors. I'll do it by filling them with $\sin$ and $\cos$ functions by using a for loop. Please remember that this time we're not seeking the most optimised code, we're simply learning at this stage.
// initialize input vectors
for (int i=0; i<n_el; i++){
h_A[i]=sin(i);
h_B[i]=cos(i);
}
Memory allocation and transfer
Now we need to allocate the memory on the GPU for the vectors we declared before. We can do this by simply using the cudaMalloc function, which takes a variable and its size as inputs. So, for us it is given by:
// allocate device vectors in the device (GPU) memory
cudaMalloc(&d_A, size);
cudaMalloc(&d_B, size);
cudaMalloc(&d_C, size);
Now we'll use another CUDA function, which is necessary to transfer data between the host and the device. The function's name is cudaMemcpy and takes four parameters. The first and the second parameters are pointers to the destination location and the source location, respectively. The third parameter specifies their size (in bytes), while the fourth is a string which specifies the transfer path. For the latter, we have three choices:
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyHostToHost
that we can use depending on what we need to do. At first, as we need to transfer data from CPU to GPU, we'll use cudaMemcpyHostToDevice, using these two lines of code:
// copy input vectors from the host (CPU) memory to the device (GPU) memory
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
This means that we are transferring from the h_A (host) location to d_A (device) location size bytes of data.
Kernel function invocation
As I've already mentioned a couple of times I prefer to split the CPU and GPU parts. In this script we don't launch the kernel directly but we just call the function containing it. We only need to write:
// call kernel function
sum(d_A, d_B, d_C, n_el);
I'll show later how to write both this function and the actual kernel. Also, I'll show you how to check for errors in later articles.
GPU to CPU and memory deallocation
This is the final part of this script. We need to transfer our output vector d_C from the device to the host and then clean the memory by deallocating our variables from GPU's memory and deleting them from the CPU.
// copy the output (results) vector from the device (GPU) memory to the host (CPU) memory
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// free host memory
delete[] h_A;
delete[] h_B;
delete[] h_C;
return cudaDeviceSynchronize();
}
In the complete code below, you can also find a section that computes the cumulative error (if any!) of this vector addition, to check if everything went fine.
Our serial code is now finished. We just have to write the kernel.
Kernel code
First, we need a header file. So click on New>Header File and when asked for a name, type kernel.h. This one is pretty easy to deal with, as we only need to declare our kernel function and a couple of more lines needed to check for errors.
// avoid definition redundancies
#ifndef KERNEL_CUH_
#define KERNEL_CUH_
void sum(const float* A, const float* B, float* C, int n_el);
#endif
As you can see, the function only takes our three arrays and the number of elements they are composed of. In essence, it is just a normal function.
But eventually the kernel has to be written. Create the last file, as usual by going to New>Source File on the menu or by clicking the specific button.
First, we have to include libraries and declare the kernel as follows:
#include <math.h>
#include "cuda_runtime.h"
#include "kernel.h"
// declare the kernel function
__global__ void kernel_sum(const float* A, const float* B, float* C, int n_el);
Second, we have to declare the function used for kernel invocation. Again, it's not mandatory to have it, but it will be useful in more complex and/or longer programs.
// function which invokes the kernel
void sum(const float* A, const float* B, float* C, int n_el) {
// declare the number of blocks per grid and the number of threads per block
int threadsPerBlock,blocksPerGrid;
// use 1 to 512 threads per block
if (n_el<512){
threadsPerBlock = n_el;
blocksPerGrid = 1;
} else {
threadsPerBlock = 512;
blocksPerGrid = ceil(double(n_el)/double(threadsPerBlock));
}
As you can see, by now this function is only used to dynamically set the number of threads per block and blocks per grid.
What follows is the most important part in today's example. This is how the kernel is invoked
// invoke the kernel
kernel_sum<<<blocksPerGrid,threadsPerBlock>>>(A, B, C, n_el);
}
This means that the kernel_sum kernel will use blocksPerGrid number of blocks and threadsPerBlock number of threads to compute the vector addition. The if statement is needed to prevent multiple threads from accessing the same portion of memory (e.g. we have two blocks of 512 threads each but n_el is 515. In this case, without that condition, threads from 516 to 1024 could do some unexpected work).
// kernel
__global__ void kernel_sum(const float* A, const float* B, float* C, int n_el)
// calculate the unique thread index
int tid = blockDim.x * blockIdx.x + threadIdx.x;
// perform tid-th elements addition
if (tid < n_el) C[tid] = A[tid] + B[tid];
}
This is the kernel, where the GPU magic happens. The element-wise addition is no different from every other function, but it's fundamental to understand how the GPU obtains its indexes. In this trivial example, we have one-dimensional vectors, so we just need to get the block index (blockDim.x * blockIdx.x) by using these built-in objects and sum the thread index (threadIdx.x) within the block to them.
Now click the Run button to launch your first GPU program!

Run button
I hope this guide has been useful. In the next few articles I'll discuss useful topics such as checking for errors, performance measurements, makefiles etc. as well as more advanced concepts in parallel computing.
Complete code
vector_addition.cpp
#include <math.h>
#include <time.h>
#include <iostream>
#include <stdexcept>
#include "cuda_runtime.h"
#include "kernel.h"
// declare the vectors' number of elements and their size in bytes
static const int n_el = 512;
static const size_t size = n_el * sizeof(float);
int main(){
// declare and allocate input vectors h_A and h_B in the host (CPU) memory
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
// declare device vectors in the device (GPU) memory
float *d_A,*d_B,*d_C;
// initialize input vectors
for (int i=0; i<n_el; i++){
h_A[i]=sin(i);
h_B[i]=cos(i);
}
// allocate device vectors in the device (GPU) memory
cudaMalloc(&d_A, size);
cudaMalloc(&d_B, size);
cudaMalloc(&d_C, size);
// copy input vectors from the host (CPU) memory to the device (GPU) memory
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// call kernel function
sum(d_A, d_B, d_C, n_el);
// copy the output (results) vector from the device (GPU) memory to the host (CPU) memory
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// compute the cumulative error
double err=0;
for (int i=0; i<n_el; i++) {
double diff=double((h_A[i]+h_B[i])-h_C[i]);
err+=diff*diff;
// print results for manual checking.
std::cout << "A+B: " << h_A[i]+h_B[i] << "\n";
std::cout << "C: " << h_C[i] << "\n";
}
err=sqrt(err);
std::cout << "err: " << err << "\n";
// free host memory
delete[] h_A;
delete[] h_B;
delete[] h_C;
return cudaDeviceSynchronize();
}
Kernel.h
// avoid definition redundancies
#ifndef KERNEL_CUH_
#define KERNEL_CUH_
void sum(const float* A, const float* B, float* C, int n_el);
#endif
Kernel.cu
#include <math.h>
#include "cuda_runtime.h"
#include "kernel.h"
// declare the kernel function
__global__ void kernel_sum(const float* A, const float* B, float* C, int n_el);
// function which invokes the kernel
void sum(const float* A, const float* B, float* C, int n_el) {
// declare the number of blocks per grid and the number of threads per block
int threadsPerBlock,blocksPerGrid;
// use 1 to 512 threads per block
if (n_el<512){
threadsPerBlock = n_el;
blocksPerGrid = 1;
} else {
threadsPerBlock = 512;
blocksPerGrid = ceil(double(n_el)/double(threadsPerBlock));
}
// invoke the kernel
kernel_sum<<<blocksPerGrid,threadsPerBlock>>>(A, B, C, n_el);
}
// kernel
__global__ void kernel_sum(const float* A, const float* B, float* C, int n_el)
{
// calculate the unique thread index
int tid = blockDim.x * blockIdx.x + threadIdx.x;
// perform tid-th elements addition
if (tid < n_el) C[tid] = A[tid] + B[tid];
}



